Cette page peut contenir du texte traduit automatiquement.
Extraction de texte depuis un PDF en C# et VB.NET
L’extraction de texte d’un document PDF est une tâche courante pour les développeurs C# et VB.NET. Vous pouvez utiliser la bibliothèque Docotic.Pdf pour extraire du texte en quelques lignes de code sous Windows, Linux, macOS, Android, iOS ou dans un environnement cloud.
Vous aurez besoin de la bibliothèque Docotic.Pdf pour essayer l’exemple de code. Obtenez la bibliothèque et une clé de licence gratuite à durée limitée sur la page Télécharger la bibliothèque PDF C# .NET.
Il existe différentes approches pour l’extraction de texte. Examinons quelques exemples pratiques.

Conversion d’un PDF en texte brut
Vous pouvez utiliser le texte brut pour l’indexation, la lecture ou une forme d’analyse du contenu PDF. Cet exemple montre comment convertir un PDF en texte en C# :
using BitMiracle.Docotic.Pdf;
using var pdf = new PdfDocument("your_document.pdf");
string documentText = pdf.GetText();
Console.WriteLine(documentText);
PdfDocument.GetText() fournit le résultat suivant pour le document d’exemple :
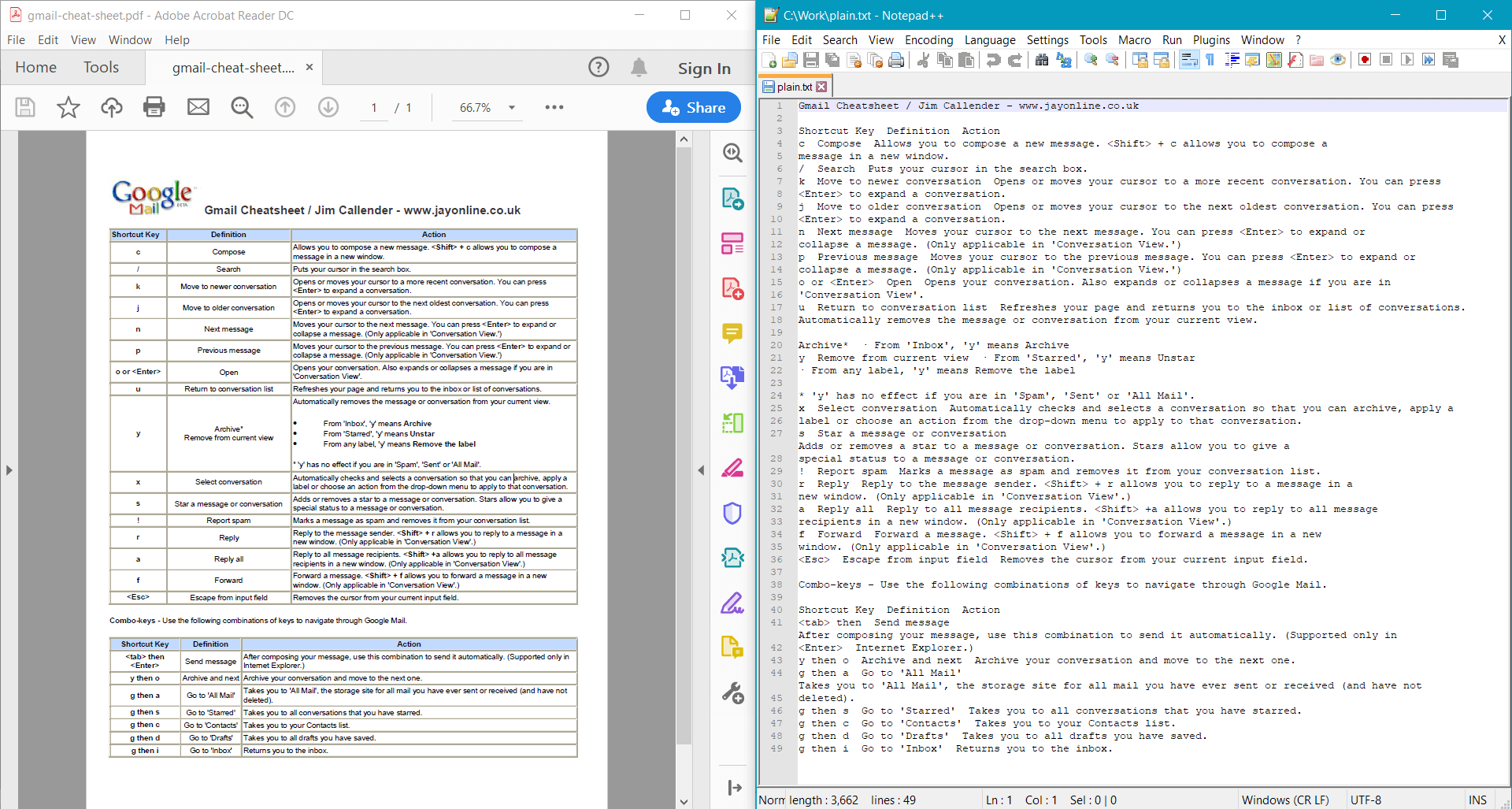
Vous pouvez également extraire le texte de pages individuelles :
using var pdf = new PdfDocument("your_document.pdf");
for (int i = 0; i < pdf.PageCount; ++i)
{
string pageText = pdf.Pages[i].GetText();
using var writer = new StreamWriter($"page_{i}.txt");
writer.Write(pageText);
}
Des exemples C# et VB.NET associés sont disponibles sur GitHub.
Conversion d’un PDF en texte formaté
Vous pouvez utiliser le texte formaté pour analyser certaines données textuelles structurées ou pour afficher le texte dans un format lisible. Cet exemple montre comment convertir un PDF en texte formaté en C# :
using var pdf = new PdfDocument("your_document.pdf");
string formattedText = pdf.GetTextWithFormatting();
// une approche alternative, page par page
_ = pdf.Pages[0].GetTextWithFormatting();
Console.WriteLine(formattedText);
PdfDocument.GetTextWithFormatting() fournit le résultat suivant pour le document d’exemple :
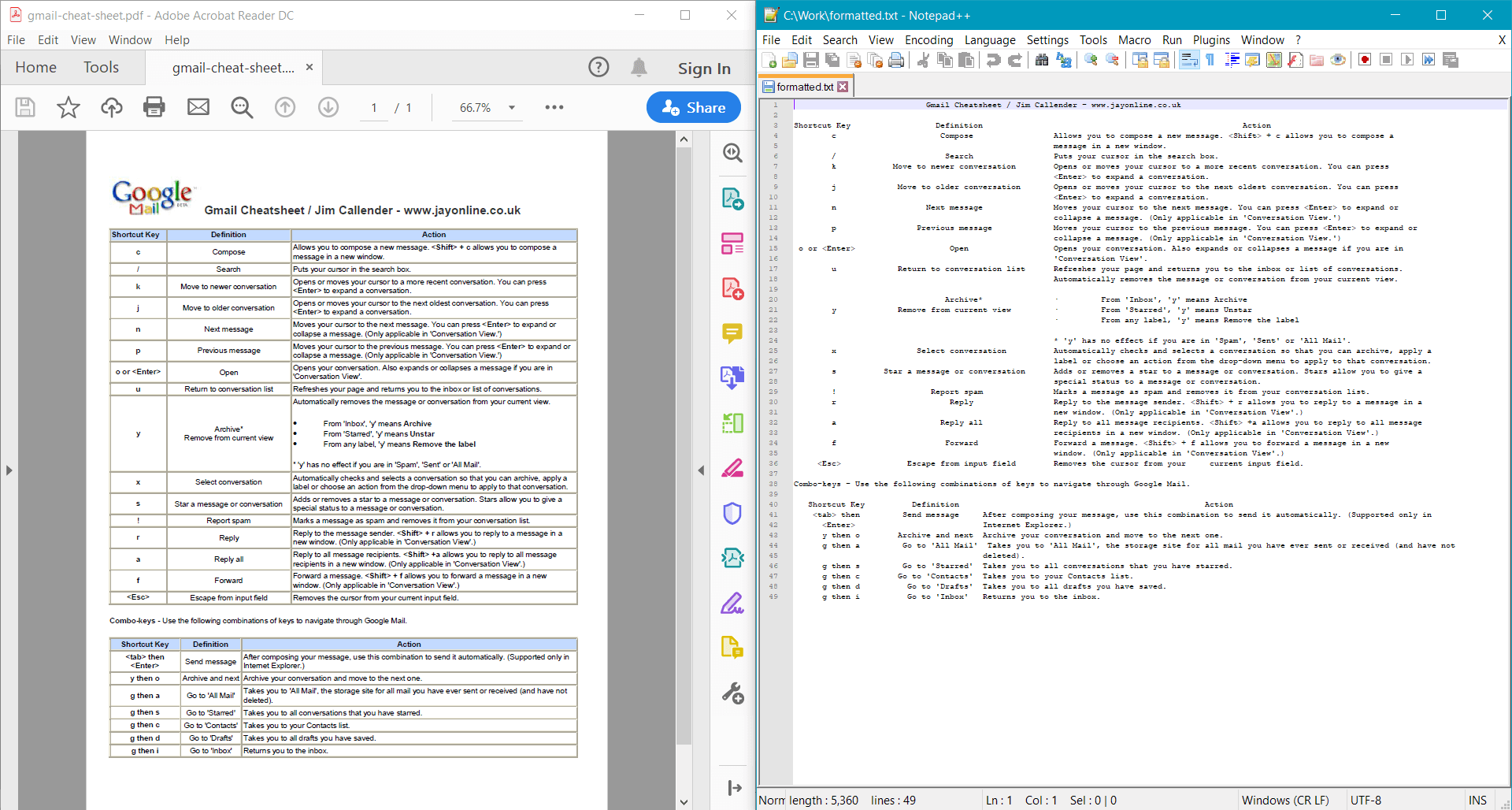
Extraction de texte brut ou formaté depuis une zone spécifique
Vous pouvez avoir besoin d’extraire le texte uniquement d’une partie spécifique d’une page PDF. Par exemple, pour analyser uniquement le texte de l’en-tête de page. La bibliothèque prend aussi cela en charge. Exemple en C# :
using var pdf = new PdfDocument("your_document.pdf");
var page = pdf.Pages[0];
var options = new PdfTextExtractionOptions
{
Rectangle = new PdfRectangle(0, 0, page.Width, 100),
WithFormatting = false
};
string areaText = page.GetText(options);
Console.WriteLine(areaText);
Cet exemple fournit le résultat suivant pour le document d’exemple :
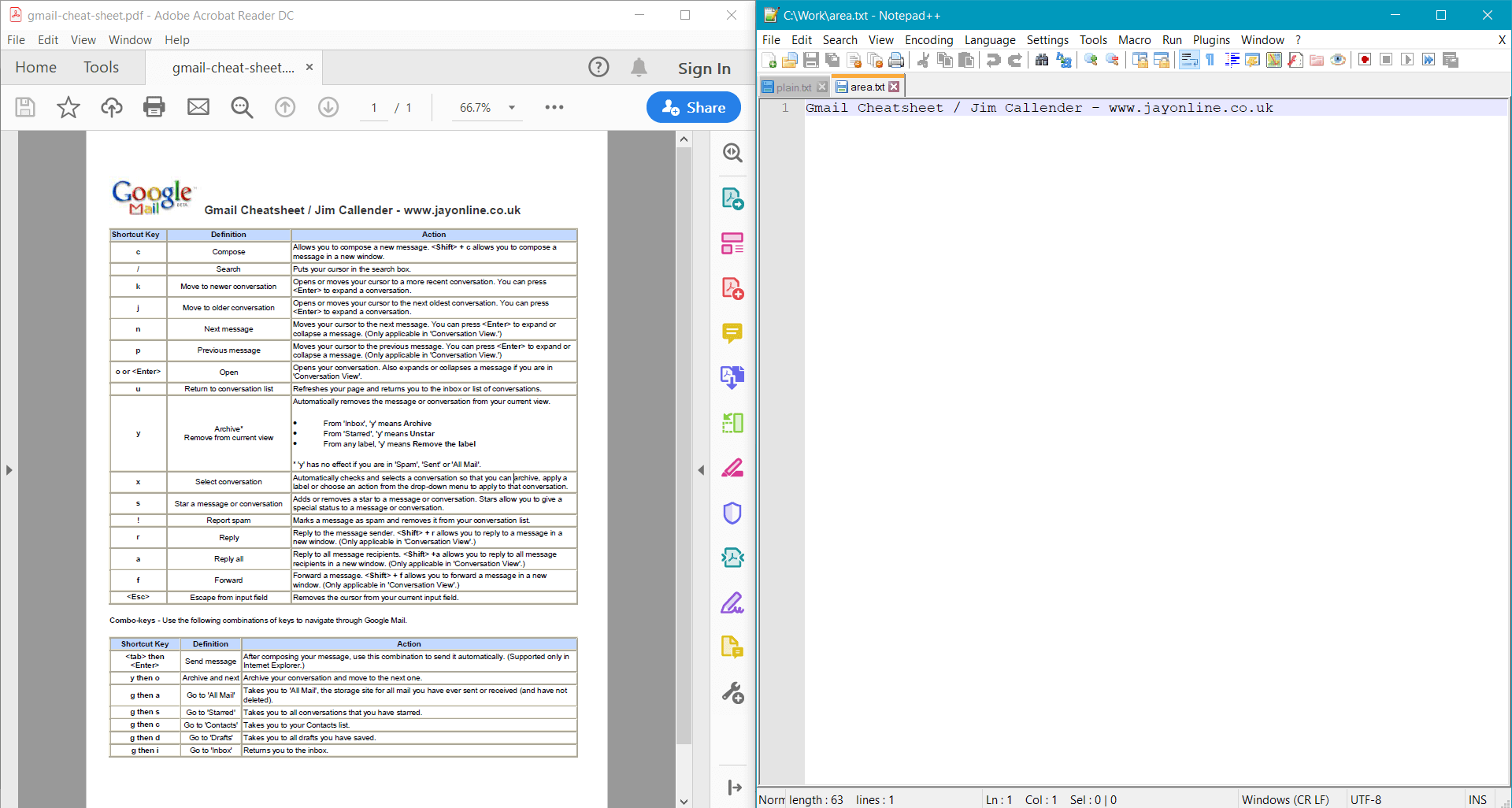
Informations détaillées sur le texte
Vous pouvez également obtenir des informations détaillées sur chaque fragment de texte pour une analyse complète. Docotic.Pdf fournit des méthodes pour extraire le texte tel quel, par mots ou par caractères. Pour chaque fragment de texte, la bibliothèque extrait :
- Texte Unicode
- Limites sur la page
- Police
- Taille de police
- Matrice de transformation, utile pour le texte mis à l’échelle ou pivoté
- Mode de rendu
- Couleur de remplissage, opacité, motif
- Style de contour
- Informations détaillées sur chaque caractère
Cet exemple montre comment extraire le texte par mots depuis une page PDF en C# :
using var pdf = new PdfDocument("your_document.pdf");
PdfPage page = pdf.Pages[0];
foreach (PdfTextData data in page.GetWords())
{
Console.WriteLine(
$"{{\n" +
$" text: '{data.GetText()}',\n" +
$" bounds: {data.Bounds},\n" +
$" font name: '{data.Font.Name}',\n" +
$" font size: {data.FontSize},\n" +
$" transformation matrix: {data.TransformationMatrix},\n" +
$" rendering mode: '{data.RenderingMode}',\n" +
$" brush: {data.Brush},\n" +
$" pen: {data.Pen}\n" +
$"}},"
);
page.Canvas.DrawRectangle(data.Bounds);
}
pdf.Save("result.pdf");
L’exemple fournit le résultat suivant pour le document d’exemple :
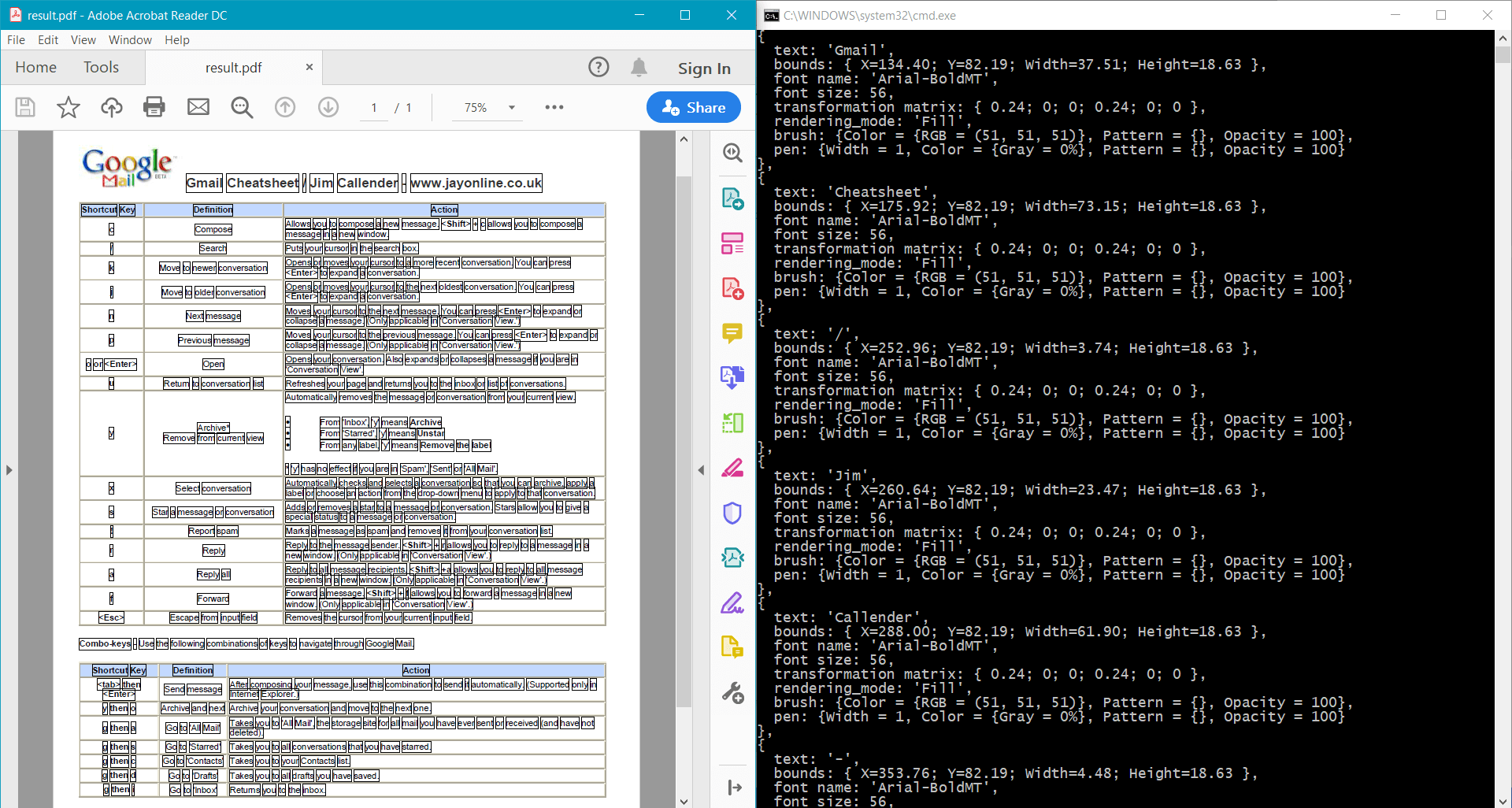
Vous pouvez utiliser les méthodes Docotic.Pdf suivantes pour obtenir des informations détaillées sur le texte :
- PdfCanvas.GetTextData() (p. ex. page.Canvas.GetTextData())
- PdfPage.GetWords()
- PdfPage.GetChars()
- PdfPage.GetObjects() (renvoie non seulement du texte, mais aussi des images et des tracés vectoriels)
Exemples GitHub associés :
- Extraire le texte par mots
- Trouver et surligner le texte
- Extraire les objets de la page
Extraction de texte de droite à gauche et bidirectionnel
Docotic.Pdf extrait correctement le texte arabe, hébreu et persan des documents PDF.
En interne, les documents PDF stockent le texte selon l’ordre visuel. Cela signifie que le texte dans les langues utilisant des scripts de droite à gauche est stocké inversé. Docotic.Pdf réorganise le texte extrait selon son ordre logique. C’est généralement ce qu’attendent les lecteurs de texte de droite à gauche.
Vous n’avez rien de spécial à faire. Utilisez simplement les extraits de code ci-dessus pour obtenir le texte RTL dans le bon ordre.
OCR (reconnaissance de texte)
Si les PDF que vous traitez contiennent des images avec du texte, vous pouvez alors extraire le texte à l’aide de la reconnaissance optique de caractères. Les exemples suivants montrent comment le faire avec Docotic.Pdf et Tesseract:
- OCR du PDF et extraction de texte
- OCR du PDF et conversion en document interrogeable
Consultez l’article OCR PDF dans .NET pour plus de détails.
Chargement des polices dans les environnements cloud
Les exemples ci-dessus fonctionnent correctement dans n’importe quel environnement - sous Windows, Linux, macOS. Sur les plateformes cloud, comme AWS Lambda, vous devrez peut-être effectuer une étape de configuration supplémentaire.
Certains documents PDF utilisent des polices non incorporées. Par défaut, Docotic.Pdf charge ces polices depuis la collection de polices système (par exemple, C:/Windows/Fonts ou /usr/share/fonts). Cependant, les plateformes cloud peuvent restreindre l’accès à ces collections de polices.
Vous pouvez déployer votre propre collection de polices courantes avec votre application. Trouvez et copiez les fichiers de polices publics dans votre projet. Marquez tous les fichiers de polices avec CopyToOutputDirectory = Always dans votre projet .NET. Pour utiliser la collection, initialisez PdfDocument avec un DirectoryFontLoader personnalisé :
PdfConfigurationOptions config = PdfConfigurationOptions.Create();
config.FontLoader = new DirectoryFontLoader(["path_to_your_font_collection"], true);
using var pdf = new PdfDocument("your_document.pdf", config);
// ...
Conclusion
Vous pouvez utiliser la bibliothèque Docotic.Pdf pour extraire du texte brut ou formaté depuis un PDF en C# et VB.NET. Vous pouvez également extraire des informations détaillées sur chaque fragment de texte. Vous pouvez télécharger Docotic.Pdf ici.
Consultez les exemples C# et VB.NET pour l’extraction de texte depuis un PDF :