该页面可以包含自动翻译的文本。
从 C# 和 VB.NET 中提取 PDF 文本
从 PDF 文档中提取文本是 C# 和 VB.NET 开发者常见的任务。你可以使用 Docotic.Pdf library 仅用几行代码就在 Windows、Linux、macOS、Android、iOS 或云环境中提取文本。
你需要 Docotic.Pdf library 才能尝试示例代码。请在 下载 C# .NET PDF 库 页面获取该库以及一个免费的限时许可证密钥。
文本提取有不同的方法。下面来看一些实际示例。

转换 PDF 为纯文本
你可以将纯文本用于索引、阅读或对 PDF 内容进行某种分析。此示例展示了如何在 C# 中将 PDF 转换为文本:
using BitMiracle.Docotic.Pdf;
using var pdf = new PdfDocument("your_document.pdf");
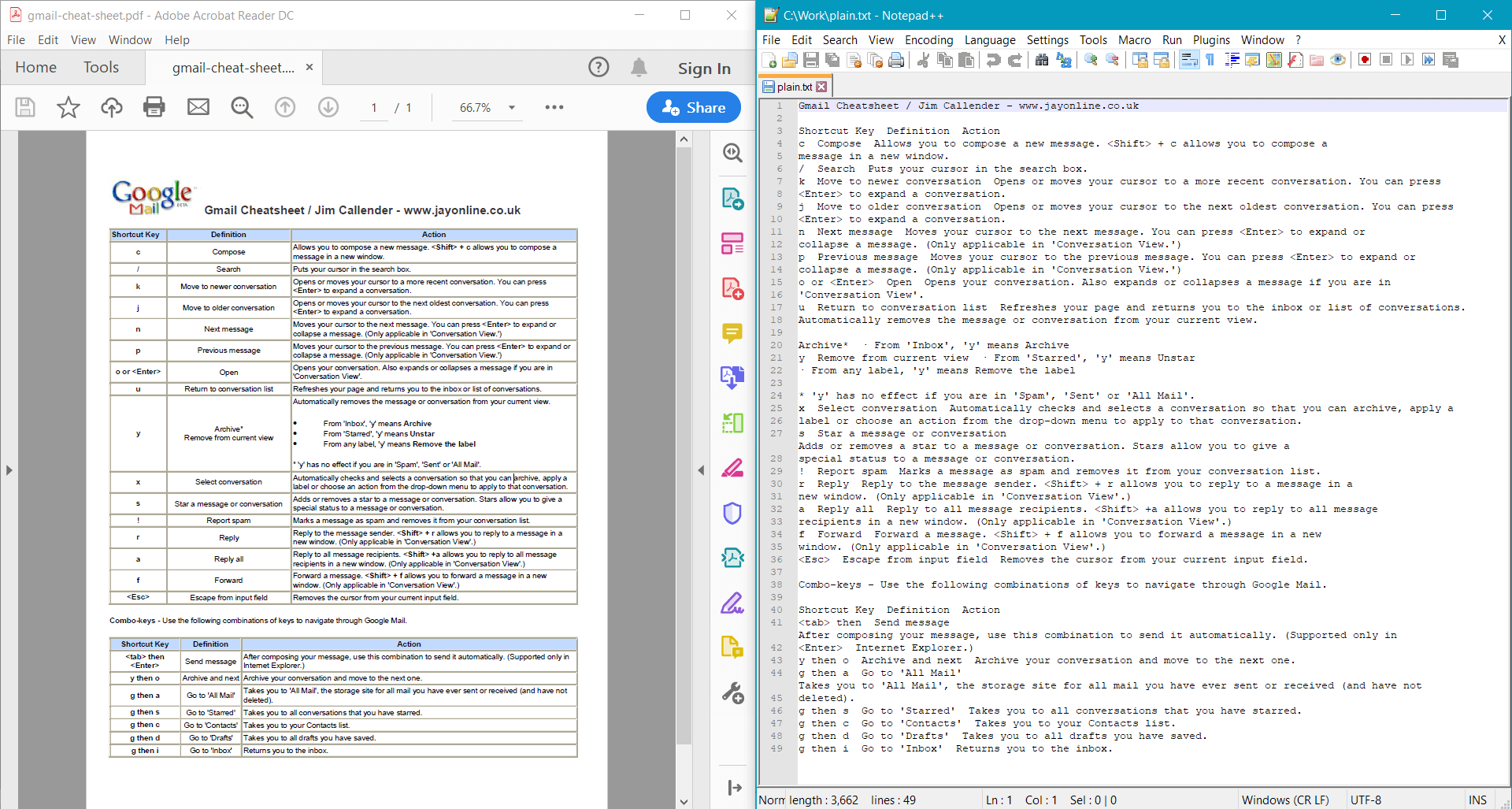
string documentText = pdf.GetText();
Console.WriteLine(documentText);
PdfDocument.GetText() 为 示例文档 提供以下结果:
或者,你也可以从单个页面提取文本:
using var pdf = new PdfDocument("your_document.pdf");
for (int i = 0; i < pdf.PageCount; ++i)
{
string pageText = pdf.Pages[i].GetText();
using var writer = new StreamWriter($"page_{i}.txt");
writer.Write(pageText);
}
相关的 C# 和 VB.NET 示例可在 GitHub 上 获取。
转换 PDF 为格式化文本
你可以使用格式化文本来解析某些结构化文本数据,或以更易读的格式显示文本。此示例展示了如何在 C# 中将 PDF 转换为格式化文本:
using var pdf = new PdfDocument("your_document.pdf");
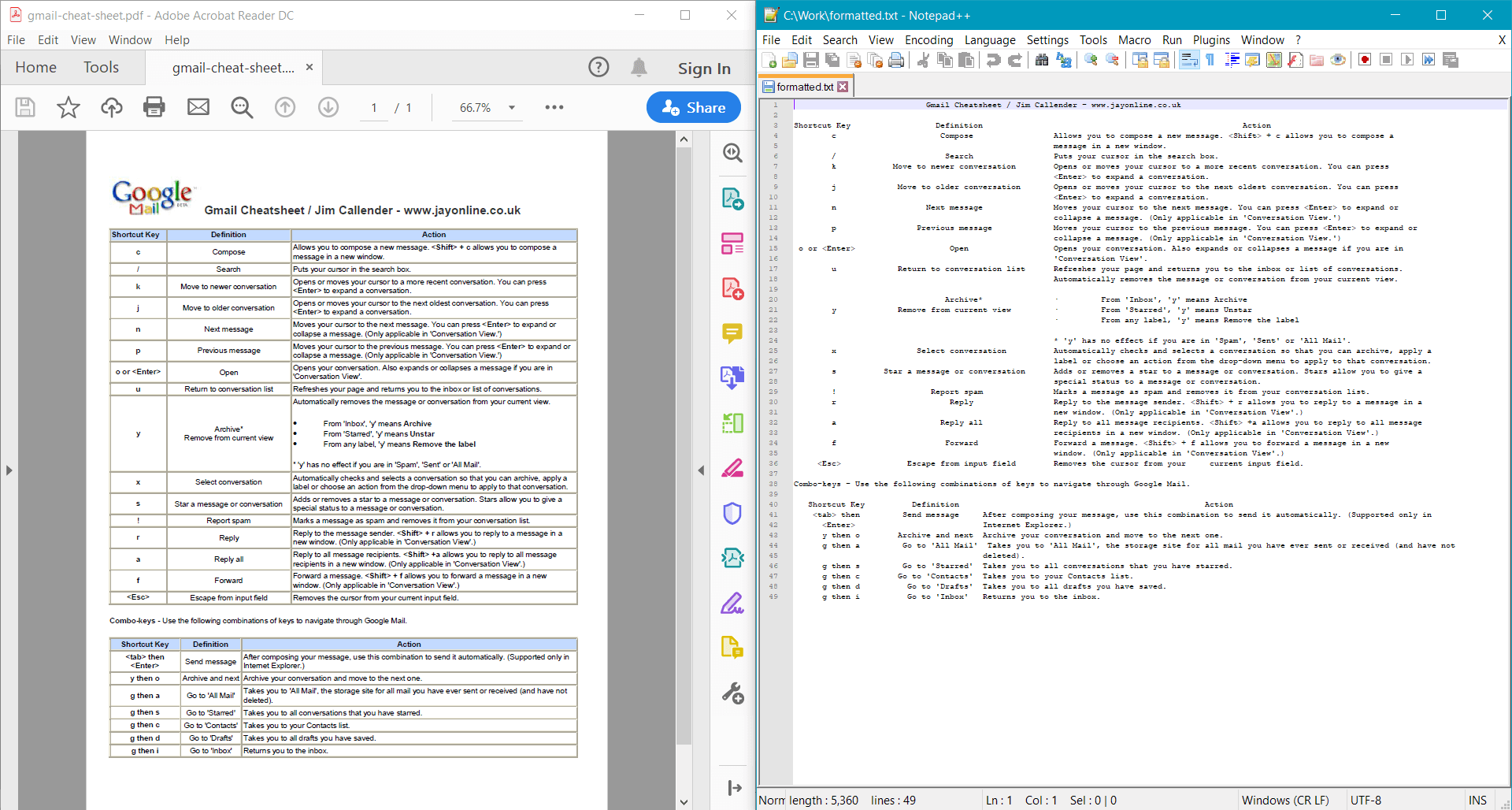
string formattedText = pdf.GetTextWithFormatting();
// 每页的另一种方法
_ = pdf.Pages[0].GetTextWithFormatting();
Console.WriteLine(formattedText);
PdfDocument.GetTextWithFormatting() 为 示例文档 提供以下结果:
从特定区域提取纯文本或格式化文本
你可能只需要从 PDF 页面的特定部分提取文本。例如,只解析页面页眉中的文本。该库也支持这一点。C# 示例:
using var pdf = new PdfDocument("your_document.pdf");
var page = pdf.Pages[0];
var options = new PdfTextExtractionOptions
{
Rectangle = new PdfRectangle(0, 0, page.Width, 100),
WithFormatting = false
};
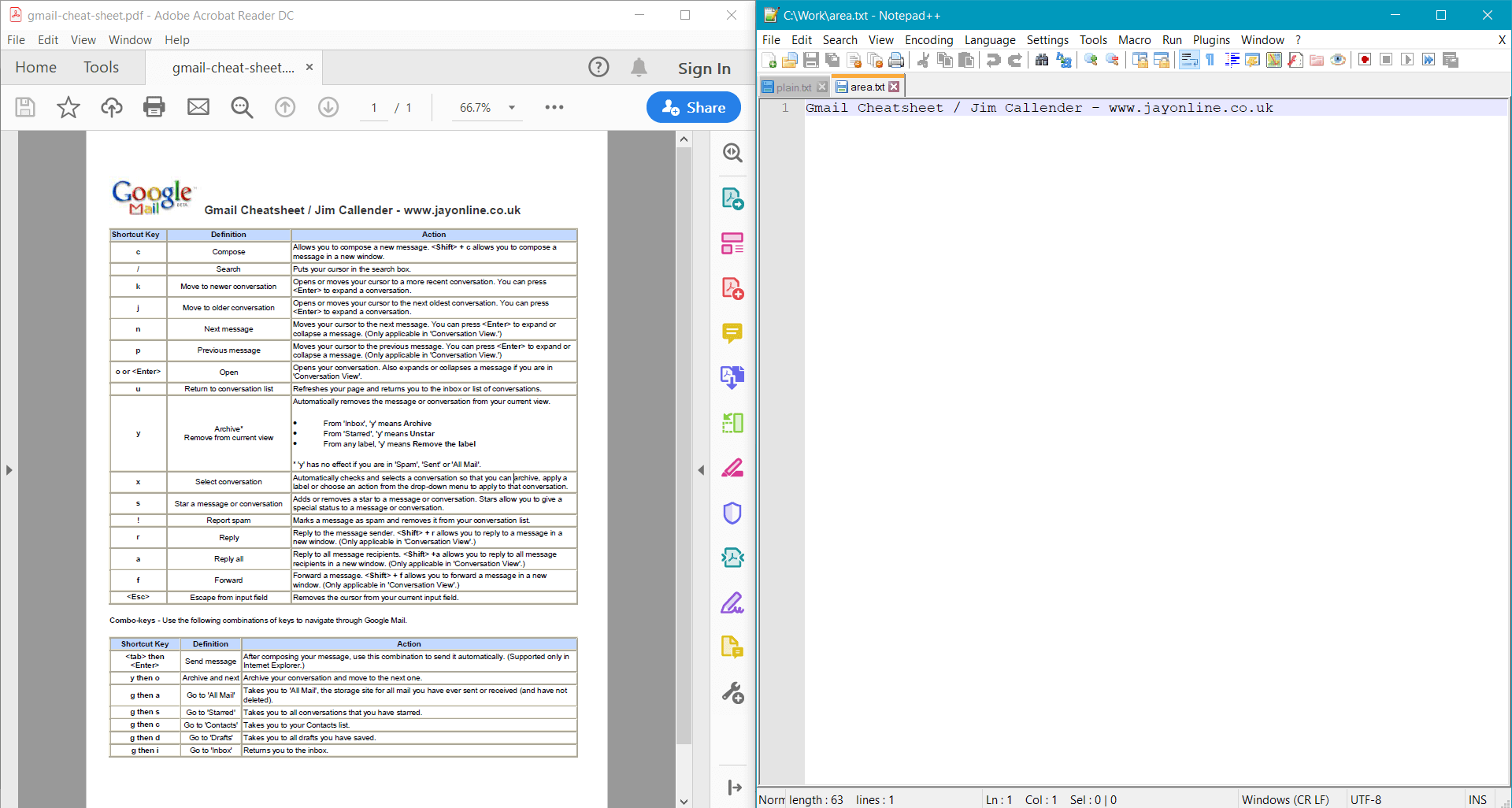
string areaText = page.GetText(options);
Console.WriteLine(areaText);
此示例为 示例文档 提供以下结果:
提取详细文本信息
你还可以获取每个文本块的详细信息,以便进行全面分析。Docotic.Pdf 提供按原样、按单词或按字符提取文本的方法。对于每个文本块,库会提取:
- Unicode 文本
- 页面上的边界框
- 字体
- 字号
- 变换矩阵,这对缩放和旋转文本很有用
- 渲染模式
- 填充颜色、不透明度、图案
- 描边样式
- 每个字符的详细信息
此示例展示了如何在 C# 中按单词从 PDF 页面提取文本:
using var pdf = new PdfDocument("your_document.pdf");
PdfPage page = pdf.Pages[0];
foreach (PdfTextData data in page.GetWords())
{
Console.WriteLine(
$"{{\n" +
$" text: '{data.GetText()}',\n" +
$" bounds: {data.Bounds},\n" +
$" font name: '{data.Font.Name}',\n" +
$" font size: {data.FontSize},\n" +
$" transformation matrix: {data.TransformationMatrix},\n" +
$" rendering mode: '{data.RenderingMode}',\n" +
$" brush: {data.Brush},\n" +
$" pen: {data.Pen}\n" +
$"}},"
);
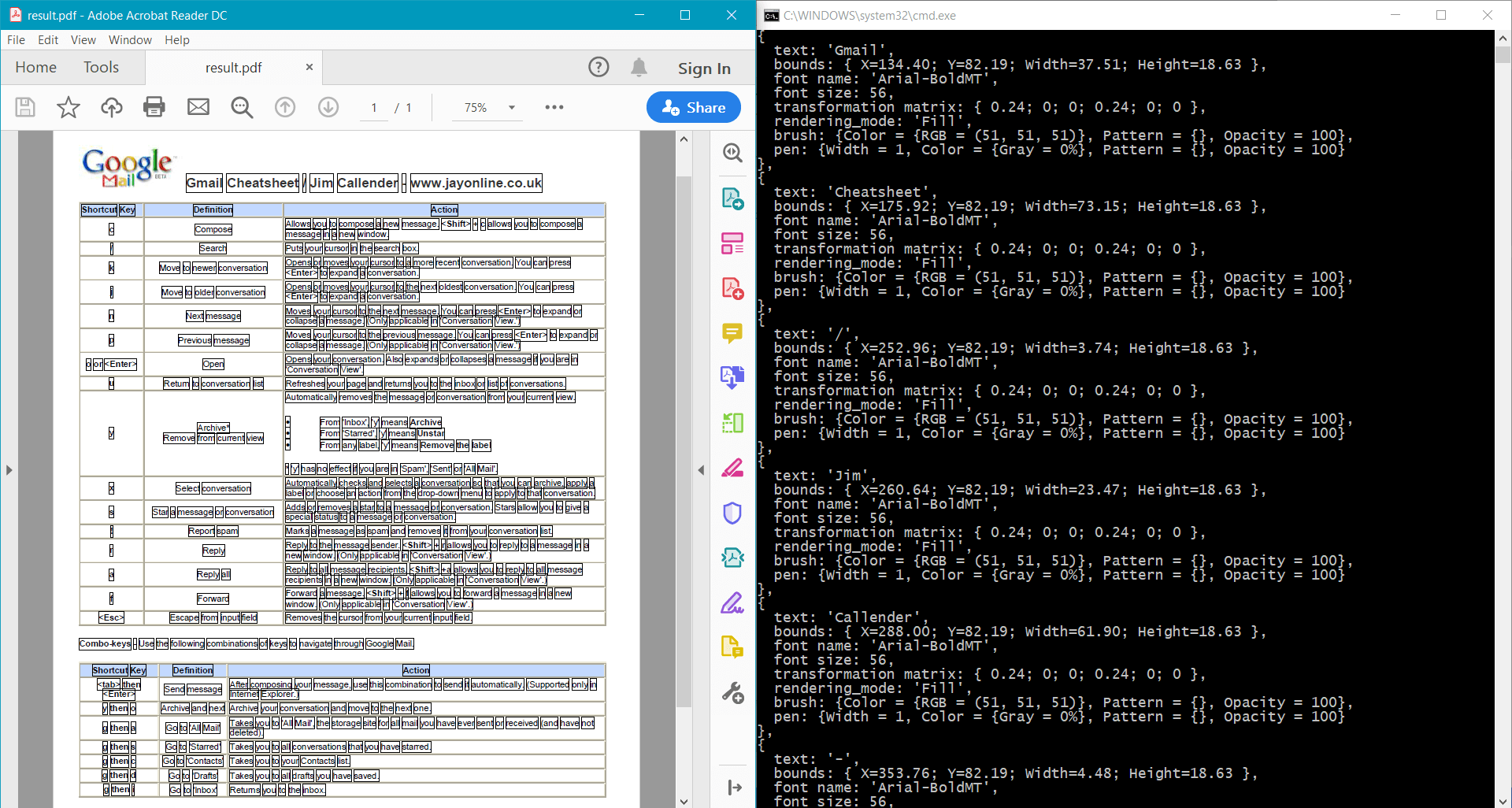
page.Canvas.DrawRectangle(data.Bounds);
}
pdf.Save("result.pdf");
此示例为 示例文档 提供以下结果:
你可以使用以下 Docotic.Pdf 方法获取详细的文本信息:
- PdfCanvas.GetTextData()(例如 page.Canvas.GetTextData())
- PdfPage.GetWords()
- PdfPage.GetChars()
- PdfPage.GetObjects()(不仅返回文本,还返回图像和矢量路径)
相关 GitHub 示例:
Docotic.Pdf 可正确从 PDF 文档中提取阿拉伯语、希伯来语和波斯语文本。
在内部,PDF 文档会按照视觉顺序存储文本。这意味着,从右到左书写的语言文本会以反向顺序存储。Docotic.Pdf 会根据逻辑顺序重新排列提取出的文本。这通常符合从右到左文本读者的预期。
你无需做任何特殊处理。只需使用上面的代码片段,即可按正确顺序获取 RTL 文本。
OCR(文本识别)
如果你处理的 PDF 包含带文本的图像,那么你可以使用 光学字符识别 提取文本。以下示例展示了如何使用 Docotic.Pdf 和 Tesseract 来实现:
- OCR PDF 并提取文本
- OCR PDF 并转换为可搜索文档
请查看 .NET 中的 OCR PDF 文章了解更多细节。
云环境中的字体加载
上面的示例在任何环境中都能正常工作——包括 Windows、Linux、macOS。在 AWS Lambda 等云平台上,你可能还需要额外执行一步配置。
有些 PDF 文档使用未嵌入的字体。默认情况下,Docotic.Pdf 会从系统字体集合中加载此类字体(例如 C:/Windows/Fonts 或 /usr/share/fonts)。不过,云平台可能会限制对这些字体集合的访问。
你可以随应用程序部署一套自己的常用字体集合。找到公共字体文件并复制到项目中。在 .NET 项目里,将所有字体文件标记为 CopyToOutputDirectory = Always。要使用该集合,请用自定义的 DirectoryFontLoader 初始化 PdfDocument:
PdfConfigurationOptions config = PdfConfigurationOptions.Create();
config.FontLoader = new DirectoryFontLoader(["path_to_your_font_collection"], true);
using var pdf = new PdfDocument("your_document.pdf", config);
// ...
结论
你可以使用 Docotic.Pdf library 从 C# 和 VB.NET 中提取纯文本或格式化文本。你还可以提取每个文本块的详细信息。你可以在 这里 下载 Docotic.Pdf。
查看用于从 PDF 提取文本的 C# 和 VB.NET 示例: