이 페이지에는 자동 번역된 텍스트가 포함될 수 있습니다.
C# 및 VB.NET에서 PDF 텍스트 추출
PDF 문서에서 텍스트를 추출하는 것은 C# 및 VB.NET 개발자에게 흔한 작업입니다. Docotic.Pdf library를 사용하면 Windows, Linux, macOS, Android, iOS 또는 클라우드 환경에서 몇 줄의 코드만으로 텍스트를 추출할 수 있습니다.
샘플 코드를 시도하려면 Docotic.Pdf 라이브러리가 필요합니다. 라이브러리와 기간 제한이 있는 무료 라이선스 키는 C# .NET PDF 라이브러리 다운로드 페이지에서 받을 수 있습니다.
텍스트 추출에는 여러 접근 방식이 있습니다. 몇 가지 실용적인 예제를 살펴보겠습니다.

일반 텍스트로 PDF 변환
일반 텍스트는 PDF 콘텐츠의 인덱싱, 읽기 또는 분석에 사용할 수 있습니다. 이 샘플은 C#에서 PDF를 텍스트로 변환하는 방법을 보여줍니다:
using BitMiracle.Docotic.Pdf;
using var pdf = new PdfDocument("your_document.pdf");
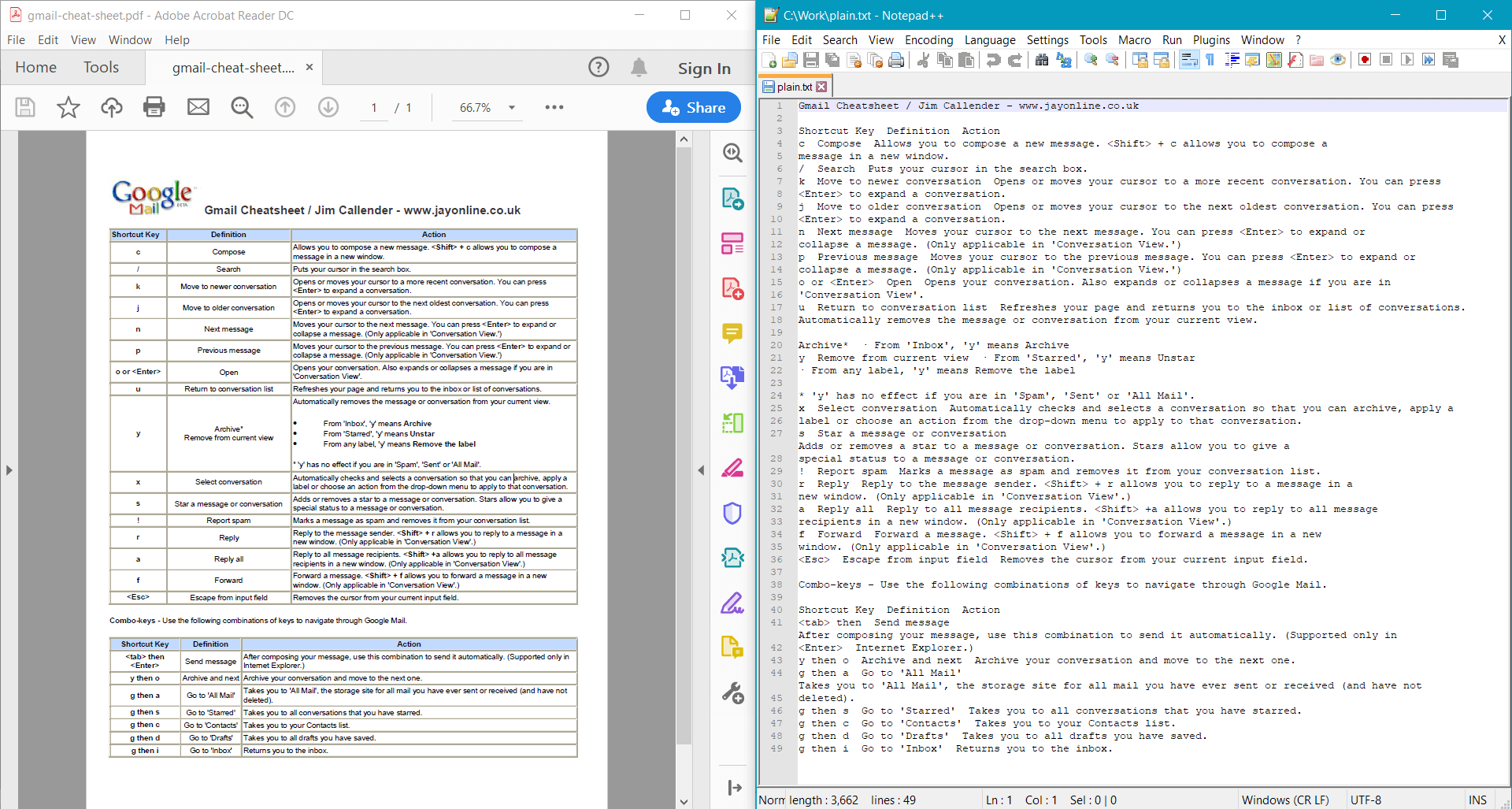
string documentText = pdf.GetText();
Console.WriteLine(documentText);
PdfDocument.GetText()는 샘플 문서에 대해 다음 결과를 제공합니다:
또는 개별 페이지에서 텍스트를 추출할 수도 있습니다:
using var pdf = new PdfDocument("your_document.pdf");
for (int i = 0; i < pdf.PageCount; ++i)
{
string pageText = pdf.Pages[i].GetText();
using var writer = new StreamWriter($"page_{i}.txt");
writer.Write(pageText);
}
관련 C# 및 VB.NET 샘플은 GitHub에서 확인할 수 있습니다.
서식 있는 텍스트로 PDF 변환
구조화된 텍스트 데이터를 구문 분석하거나 사람이 읽기 쉬운 형식으로 텍스트를 표시하려는 경우 서식 있는 텍스트를 사용할 수 있습니다. 이 샘플은 C#에서 PDF를 서식 있는 텍스트로 변환하는 방법을 보여줍니다:
using var pdf = new PdfDocument("your_document.pdf");
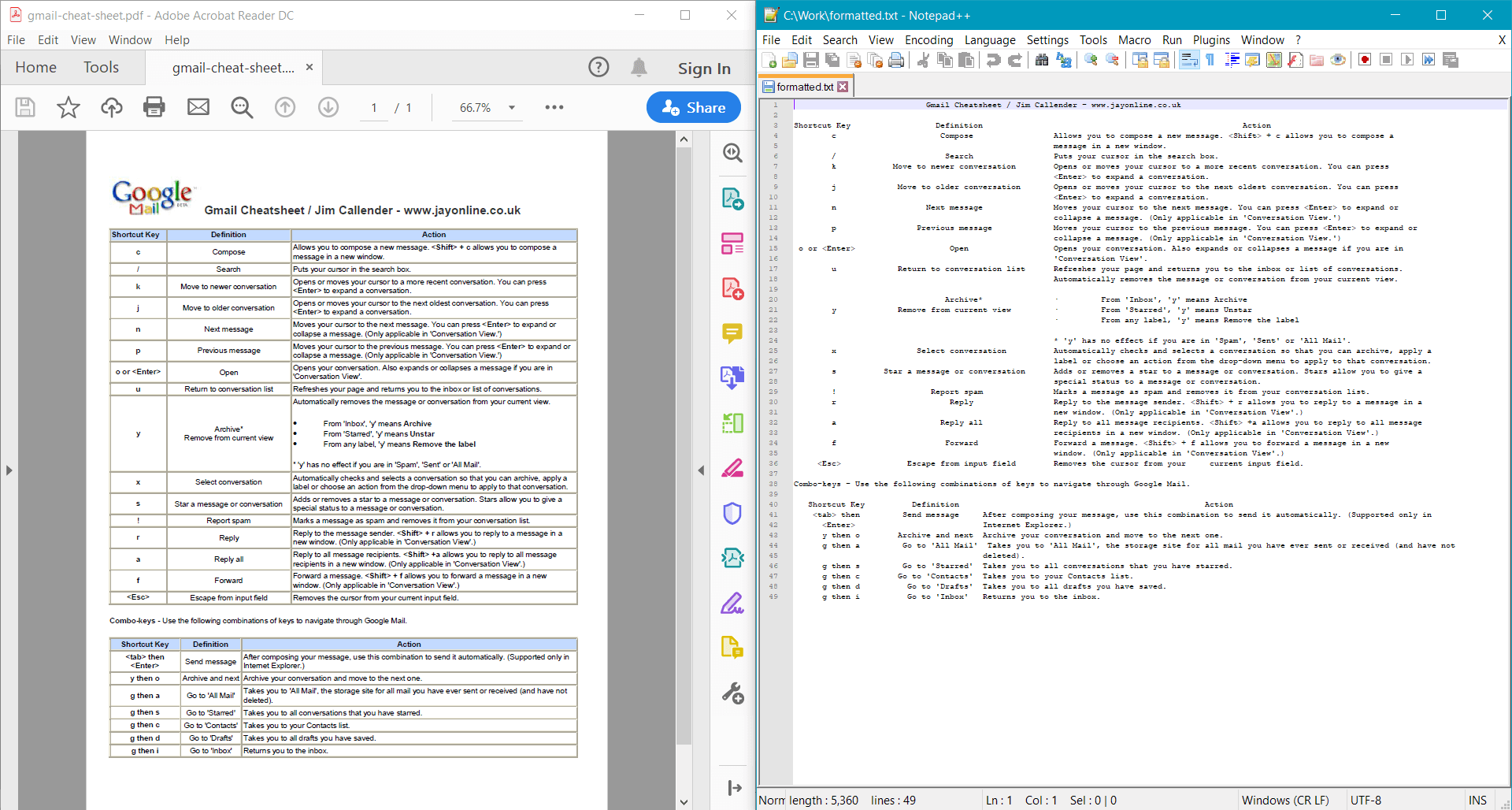
string formattedText = pdf.GetTextWithFormatting();
// 페이지별 대안 접근 방식
_ = pdf.Pages[0].GetTextWithFormatting();
Console.WriteLine(formattedText);
PdfDocument.GetTextWithFormatting()는 샘플 문서에 대해 다음 결과를 제공합니다:
특정 영역에서 일반 또는 서식 있는 텍스트 추출
PDF 페이지의 특정 부분에서만 텍스트를 추출해야 할 수 있습니다. 예를 들어 페이지 헤더의 텍스트만 구문 분석하려는 경우입니다. 라이브러리도 이를 지원합니다. C# 샘플:
using var pdf = new PdfDocument("your_document.pdf");
var page = pdf.Pages[0];
var options = new PdfTextExtractionOptions
{
Rectangle = new PdfRectangle(0, 0, page.Width, 100),
WithFormatting = false
};
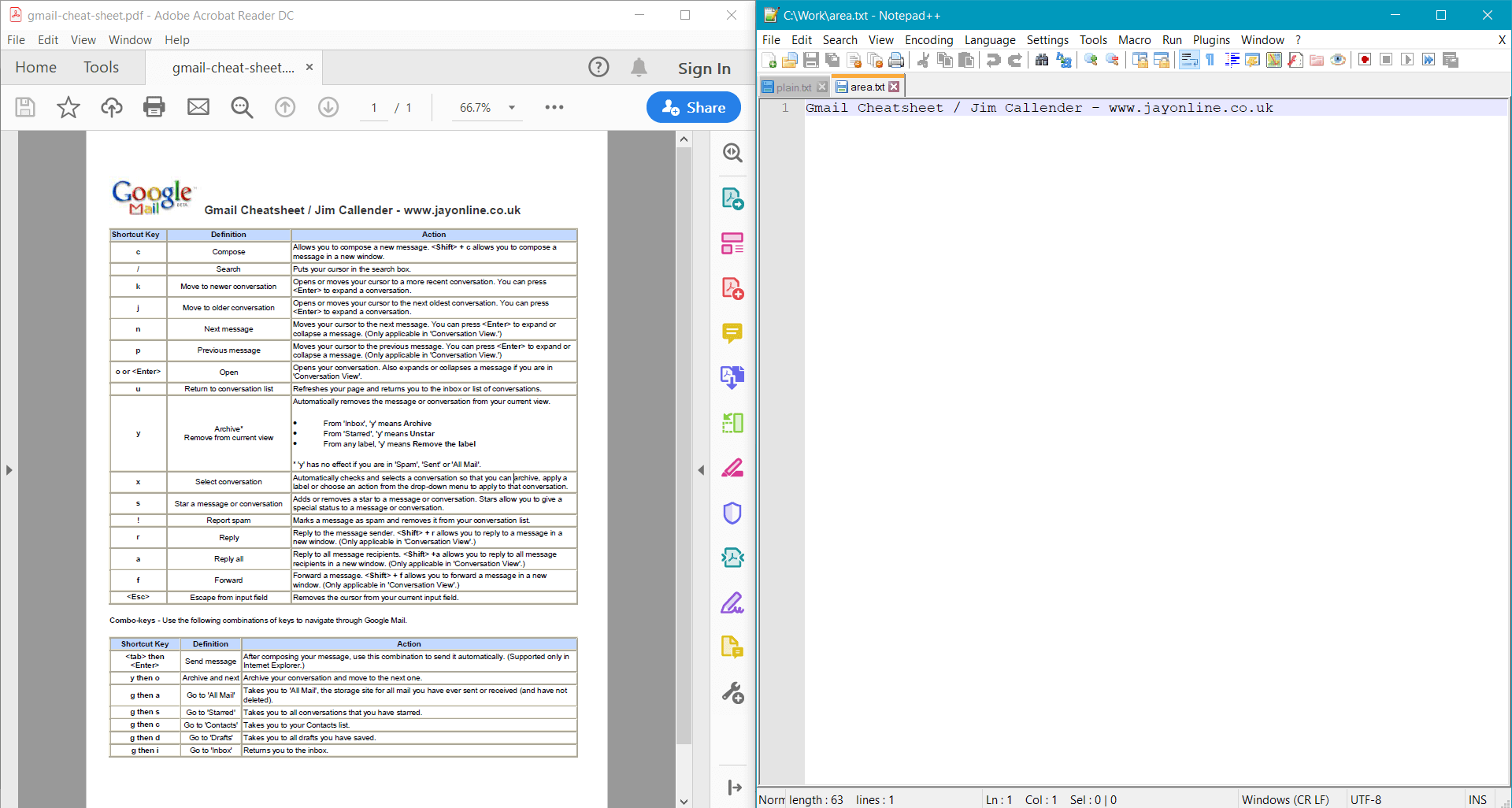
string areaText = page.GetText(options);
Console.WriteLine(areaText);
이 샘플은 샘플 문서에 대해 다음 결과를 제공합니다:
상세 텍스트 정보 추출
포괄적인 분석을 위해 각 텍스트 청크에 대한 자세한 정보도 얻을 수 있습니다. Docotic.Pdf는 텍스트를 있는 그대로, 단어별로 또는 문자별로 추출하는 메서드를 제공합니다. 각 텍스트 청크에 대해 라이브러리는 다음을 추출합니다:
- 유니코드 텍스트
- 페이지상의 경계
- 글꼴
- 글꼴 크기
- 크기 조정 및 회전된 텍스트에 유용한 변환 행렬
- 렌더링 모드
- 채우기 색상, 불투명도, 패턴
- 윤곽선 스타일
- 각 문자에 대한 상세 정보
이 샘플은 C#에서 PDF 페이지의 단어 단위로 텍스트를 추출하는 방법을 보여줍니다:
using var pdf = new PdfDocument("your_document.pdf");
PdfPage page = pdf.Pages[0];
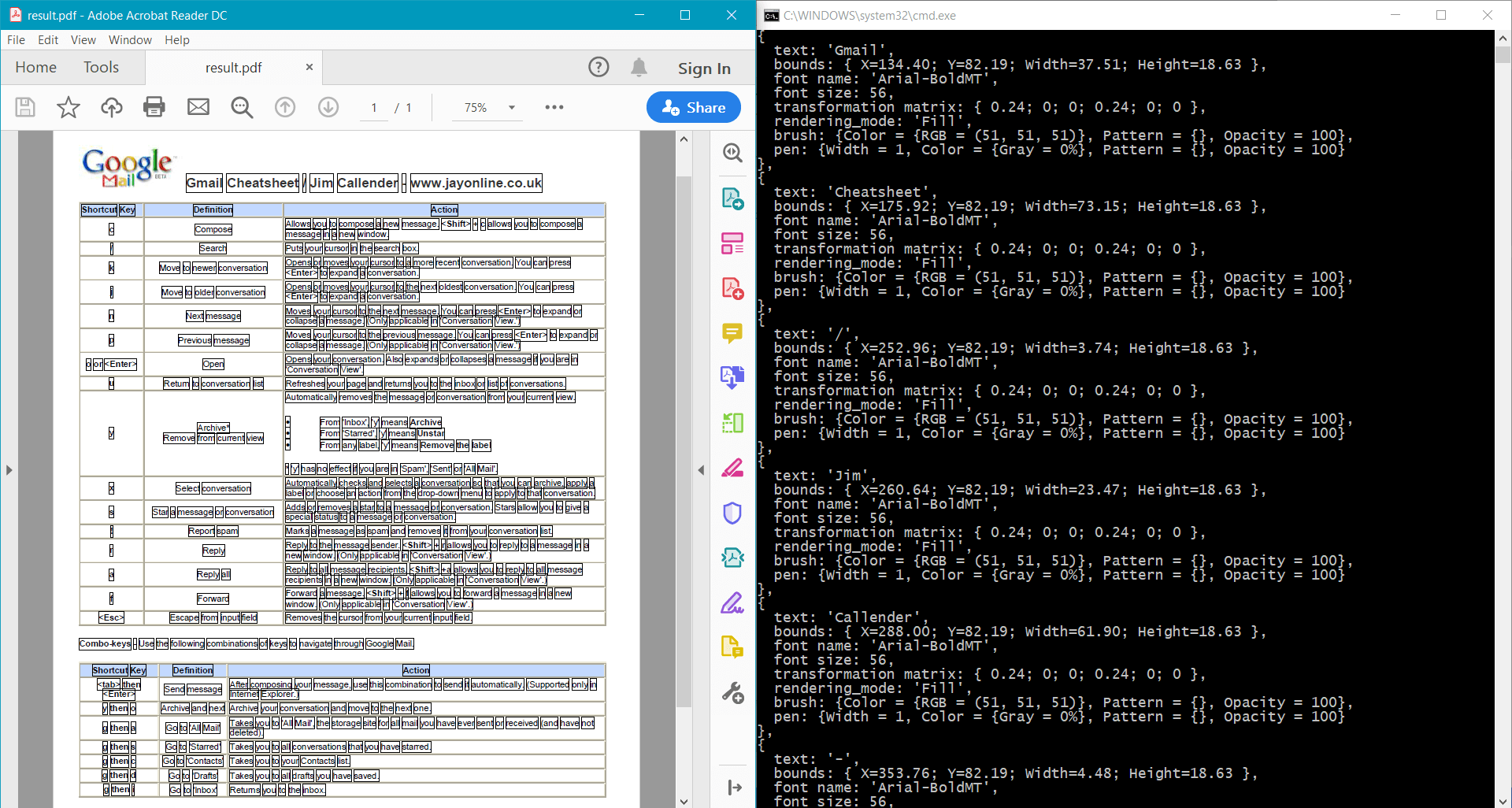
foreach (PdfTextData data in page.GetWords())
{
Console.WriteLine(
$"{{\n" +
$" text: '{data.GetText()}',\n" +
$" bounds: {data.Bounds},\n" +
$" font name: '{data.Font.Name}',\n" +
$" font size: {data.FontSize},\n" +
$" transformation matrix: {data.TransformationMatrix},\n" +
$" rendering mode: '{data.RenderingMode}',\n" +
$" brush: {data.Brush},\n" +
$" pen: {data.Pen}\n" +
$"}},"
);
page.Canvas.DrawRectangle(data.Bounds);
}
pdf.Save("result.pdf");
이 샘플은 샘플 문서에 대해 다음 결과를 제공합니다:
상세 텍스트 정보를 얻기 위해 다음 Docotic.Pdf 메서드를 사용할 수 있습니다:
- PdfCanvas.GetTextData() (예: page.Canvas.GetTextData())
- PdfPage.GetWords()
- PdfPage.GetChars()
- PdfPage.GetObjects() (텍스트뿐 아니라 이미지와 벡터 경로도 반환합니다)
관련 GitHub 샘플:
- 단어 단위로 텍스트 추출
- 텍스트 찾기 및 강조 표시
- 페이지 객체 추출
오른쪽에서 왼쪽 및 양방향 텍스트 추출
Docotic.Pdf는 PDF 문서에서 아랍어, 히브리어, 페르시아어 텍스트를 올바르게 추출합니다.
내부적으로 PDF 문서는 텍스트를 시각적 순서에 따라 저장합니다. 즉, 오른쪽에서 왼쪽으로 쓰는 스크립트를 사용하는 언어의 텍스트는 역순으로 저장됩니다. Docotic.Pdf는 추출된 텍스트를 논리적 순서에 맞게 다시 정렬합니다. 이는 일반적으로 오른쪽에서 왼쪽으로 쓰는 텍스트의 독자가 기대하는 동작입니다.
별도의 작업은 필요하지 않습니다. 위의 코드 스니펫을 사용하면 RTL 텍스트를 올바른 순서로 가져올 수 있습니다.
OCR(텍스트 인식)
다루는 PDF에 텍스트가 포함된 이미지가 있다면 광학 문자 인식을 사용하여 텍스트를 추출할 수 있습니다. 다음 샘플은 Docotic.Pdf와 Tesseract를 사용하여 이를 수행하는 방법을 보여줍니다:
- OCR PDF 및 텍스트 추출
- OCR PDF 및 검색 가능한 문서로 변환
자세한 내용은 .NET에서 PDF OCR 문서를 참조하세요.
클라우드 환경에서 폰트 로딩
위 샘플은 Windows, Linux, macOS를 포함한 모든 환경에서 잘 작동합니다. AWS Lambda 같은 클라우드 플랫폼에서는 추가 구성 단계가 하나 필요할 수 있습니다.
임베디드되지 않은 글꼴을 사용하는 PDF 문서가 있습니다. 기본적으로 Docotic.Pdf는 이러한 글꼴을 시스템 글꼴 컬렉션(예: C:/Windows/Fonts 또는 /usr/share/fonts)에서 로드합니다. 그러나 클라우드 플랫폼에서는 이러한 글꼴 컬렉션에 대한 접근이 제한될 수 있습니다.
일반적으로 사용되는 글꼴 컬렉션을 애플리케이션과 함께 배포할 수 있습니다. 공개 글꼴 파일을 찾아 프로젝트에 복사하세요. .NET 프로젝트에서 모든 글꼴 파일에 CopyToOutputDirectory = Always를 설정하세요. 컬렉션을 사용하려면 사용자 지정 DirectoryFontLoader로 PdfDocument를 초기화합니다:
PdfConfigurationOptions config = PdfConfigurationOptions.Create();
config.FontLoader = new DirectoryFontLoader(["path_to_your_font_collection"], true);
using var pdf = new PdfDocument("your_document.pdf", config);
// ...
결론
Docotic.Pdf library를 사용하여 C# 및 VB.NET에서 PDF의 일반 텍스트 또는 서식 있는 텍스트를 추출할 수 있습니다. 각 텍스트 청크에 대한 자세한 정보도 추출할 수 있습니다. Docotic.Pdf는 여기에서 다운로드할 수 있습니다.
PDF에서 텍스트를 추출하는 C# 및 VB.NET 샘플을 살펴보세요: