このページには自動翻訳されたテキストを含めることができます。
PDF から C# と VB.NET でテキストを抽出する
PDF ドキュメントからテキストを抽出することは、C# と VB.NET の開発者にとって一般的な作業です。Docotic.Pdf ライブラリ を使用すると、Windows、Linux、macOS、Android、iOS、またはクラウド環境で、わずか数行のコードでテキストを抽出できます。
サンプルコードを試すには Docotic.Pdf ライブラリが必要です。C# .NET PDF ライブラリをダウンロード ページでライブラリと期間限定の無料ライセンス キーを入手してください。
テキスト抽出にはさまざまなアプローチがあります。いくつかの実用例を見てみましょう。

PDF をプレーン テキストに変換する
プレーン テキストは、PDF コンテンツのインデックス作成、読み取り、または分析に使用できます。このサンプルでは、C# で PDF をテキストに変換する方法を示します。
using BitMiracle.Docotic.Pdf;
using var pdf = new PdfDocument("your_document.pdf");
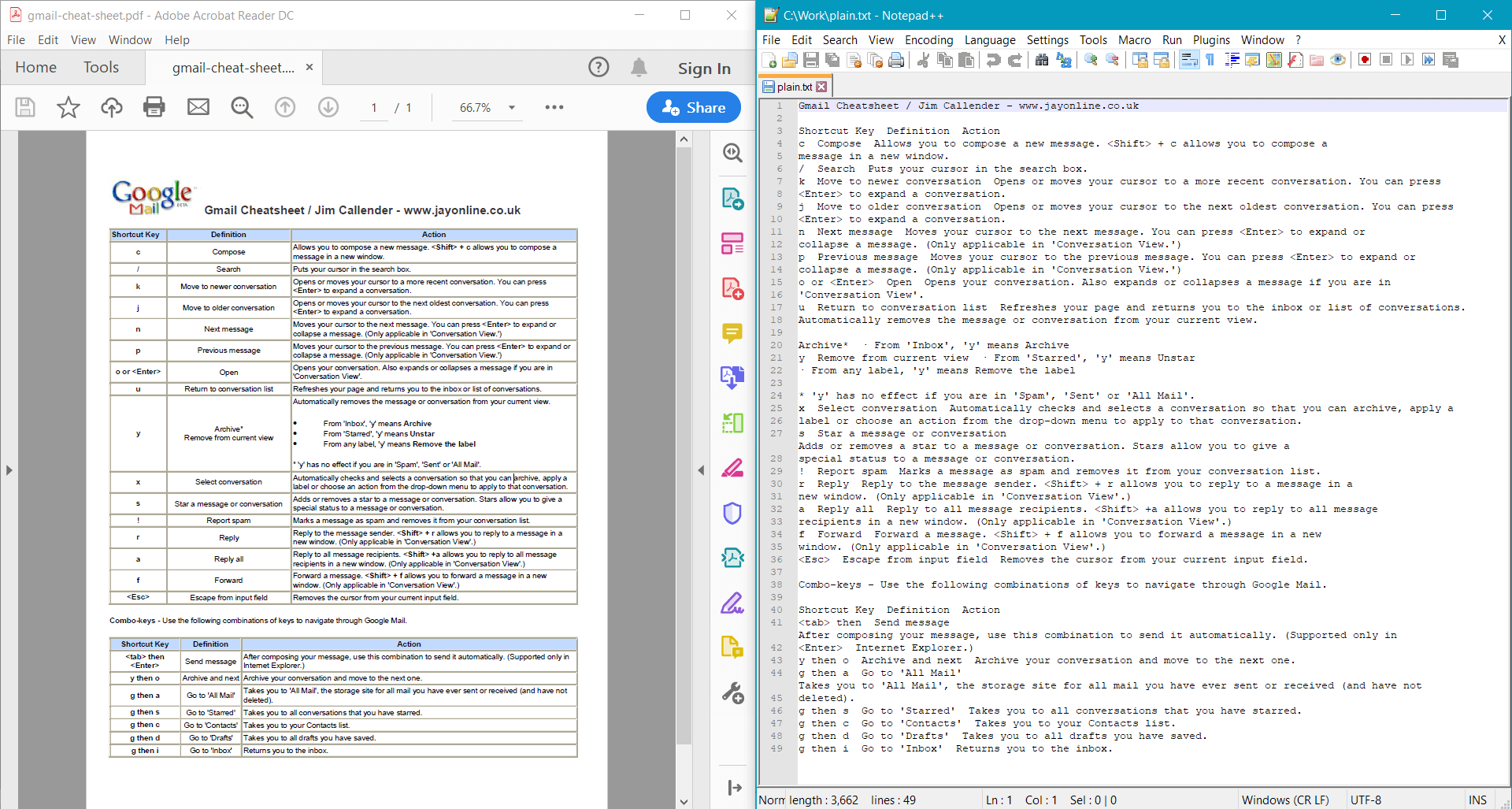
string documentText = pdf.GetText();
Console.WriteLine(documentText);
PdfDocument.GetText() は、サンプル ドキュメント に対して次の結果を返します。
また、個々のページからテキストを抽出することもできます。
using var pdf = new PdfDocument("your_document.pdf");
for (int i = 0; i < pdf.PageCount; ++i)
{
string pageText = pdf.Pages[i].GetText();
using var writer = new StreamWriter($"page_{i}.txt");
writer.Write(pageText);
}
関連する C# と VB.NET のサンプルは GitHub で 入手できます。
PDF を整形済みテキストに変換する
整形済みテキストは、構造化されたテキスト データを解析したり、人間が読みやすい形式でテキストを表示したりする場合に使用できます。このサンプルでは、C# で PDF を整形済みテキストに変換する方法を示します。
using var pdf = new PdfDocument("your_document.pdf");
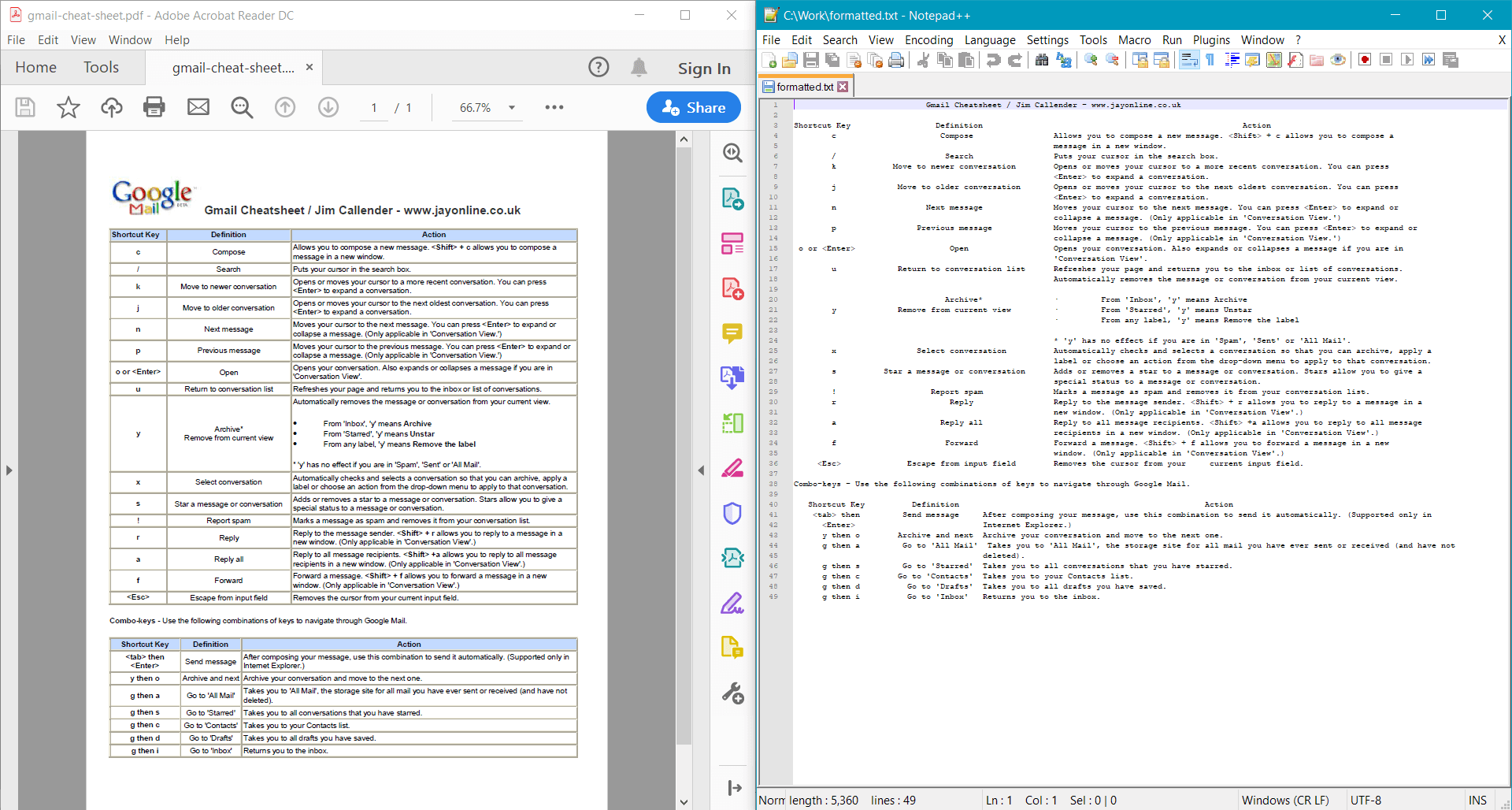
string formattedText = pdf.GetTextWithFormatting();
// ページごとの代替アプローチ
_ = pdf.Pages[0].GetTextWithFormatting();
Console.WriteLine(formattedText);
PdfDocument.GetTextWithFormatting() は、サンプル ドキュメント に対して次の結果を返します。
特定の領域からプレーンまたは整形済みテキストを抽出する
PDF ページの特定の部分だけからテキストを抽出する必要がある場合があります。たとえば、ページ ヘッダー内のテキストだけを解析する場合です。ライブラリはこれもサポートしています。C# のサンプル:
using var pdf = new PdfDocument("your_document.pdf");
var page = pdf.Pages[0];
var options = new PdfTextExtractionOptions
{
Rectangle = new PdfRectangle(0, 0, page.Width, 100),
WithFormatting = false
};
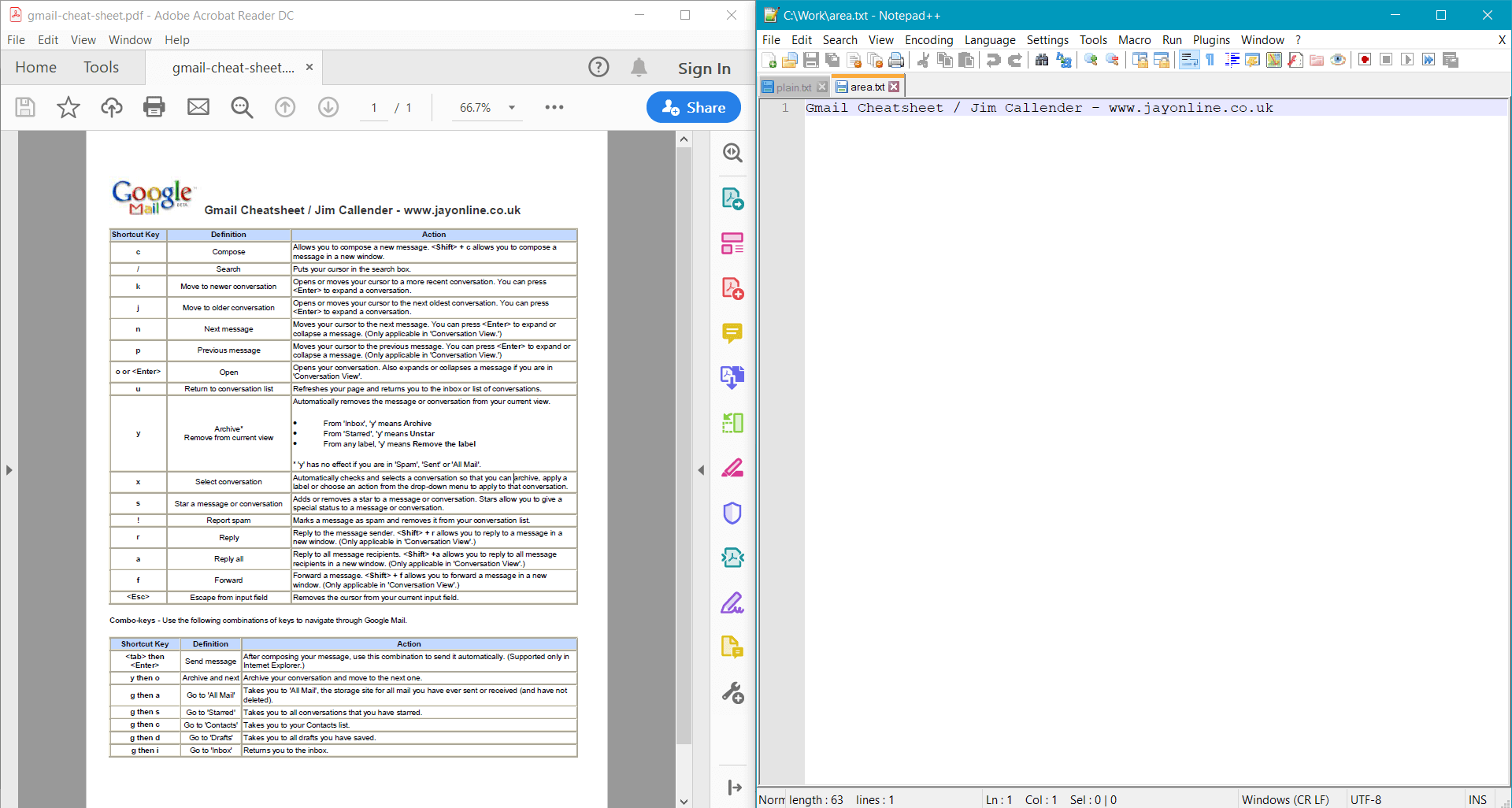
string areaText = page.GetText(options);
Console.WriteLine(areaText);
このサンプルでは、サンプル ドキュメント に対して次の結果を返します。
詳細なテキスト情報を抽出する
包括的な分析のために、各テキスト チャンクの詳細情報を取得することもできます。Docotic.Pdf には、テキストをそのまま、単語単位、または文字単位で抽出するメソッドがあります。各テキスト チャンクについて、ライブラリは次を抽出します。
- Unicode テキスト
- ページ上の境界
- フォント
- フォント サイズ
- 変換行列。拡大・回転されたテキストに有用です
- 描画モード
- 塗りつぶし色、透明度、パターン
- 輪郭スタイル
- 各文字の詳細情報
このサンプルでは、C# で PDF ページから単語単位でテキストを抽出する方法を示します。
using var pdf = new PdfDocument("your_document.pdf");
PdfPage page = pdf.Pages[0];
foreach (PdfTextData data in page.GetWords())
{
Console.WriteLine(
$"{{\n" +
$" text: '{data.GetText()}',\n" +
$" bounds: {data.Bounds},\n" +
$" font name: '{data.Font.Name}',\n" +
$" font size: {data.FontSize},\n" +
$" transformation matrix: {data.TransformationMatrix},\n" +
$" rendering mode: '{data.RenderingMode}',\n" +
$" brush: {data.Brush},\n" +
$" pen: {data.Pen}\n" +
$"}},"
);
page.Canvas.DrawRectangle(data.Bounds);
}
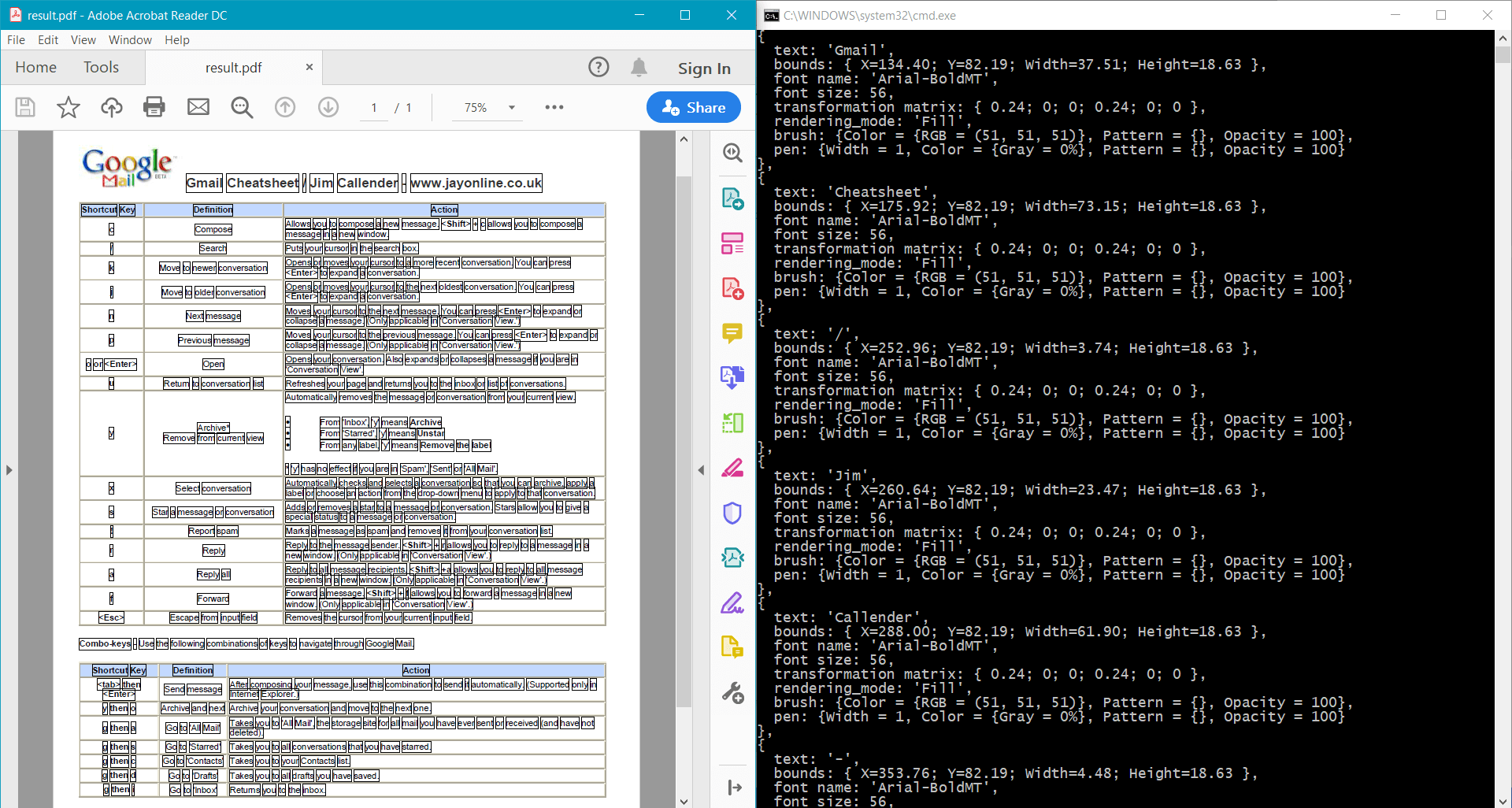
pdf.Save("result.pdf");
このサンプルでは、サンプル ドキュメント に対して次の結果を返します。
詳細なテキスト情報を取得するには、次の Docotic.Pdf メソッドを使用できます。
- PdfCanvas.GetTextData()(例: page.Canvas.GetTextData())
- PdfPage.GetWords()
- PdfPage.GetChars()
- PdfPage.GetObjects()(テキストだけでなく、画像やベクター パスも返します)
関連する GitHub サンプル:
- 単語単位でテキストを抽出する
- テキストを検索して強調表示する
- ページ オブジェクトを抽出する
右から左へのテキストと双方向テキストを抽出する
Docotic.Pdf は、アラビア語、ヘブライ語、ペルシア語のテキストを PDF ドキュメントから正しく抽出します。
内部的には、PDF ドキュメントは視覚順に従ってテキストを格納します。つまり、右から左へのスクリプトを持つ言語のテキストは反転して格納されます。Docotic.Pdf は、抽出したテキストを論理順に従って並べ替えます。これは、右から左へのテキストの読者が通常期待する動作です。
特別なことをする必要はありません。上記のコード スニペットを使うだけで、RTL テキストを正しい順序で取得できます。
OCR(テキスト認識)
扱う PDF にテキストを含む画像がある場合は、光学式文字認識 を使用してテキストを抽出できます。次のサンプルでは、Docotic.Pdf と Tesseract を使ってその方法を示します。
- OCR PDF からテキストを抽出する
- OCR PDF を検索可能なドキュメントに変換する
詳細については、記事 .NET での OCR PDF を参照してください。
クラウド環境でのフォント読み込み
上記のサンプルは、Windows、Linux、macOS のいずれの環境でも問題なく動作します。AWS Lambda のようなクラウド プラットフォームでは、追加で 1 つの設定手順が必要になる場合があります。
埋め込みフォントを使用しない PDF ドキュメントがあります。既定では、Docotic.Pdf はそのようなフォントをシステム フォント コレクション(たとえば C:/Windows/Fonts や /usr/share/fonts)から読み込みます。ただし、クラウド プラットフォームでは、これらのフォント コレクションへのアクセスが制限される場合があります。
アプリケーションと一緒に、一般的なフォントの独自コレクションを配置できます。公開フォント ファイルを見つけてプロジェクトにコピーしてください。.NET プロジェクトで、すべてのフォント ファイルを CopyToOutputDirectory = Always に設定します。コレクションを使用するには、カスタムの DirectoryFontLoader で PdfDocument を初期化します。
PdfConfigurationOptions config = PdfConfigurationOptions.Create();
config.FontLoader = new DirectoryFontLoader(["path_to_your_font_collection"], true);
using var pdf = new PdfDocument("your_document.pdf", config);
// ...
結論
Docotic.Pdf ライブラリ を使用すると、C# と VB.NET で PDF からプレーン テキストまたは整形済みテキストを抽出できます。各テキスト チャンクの詳細情報も抽出できます。Docotic.Pdf は ここ からダウンロードできます。
PDF からテキストを抽出する C# と VB.NET のサンプルを参照してください。