Questa pagina può contenere testo tradotto automaticamente.
Estrarre testo da PDF in C# e VB.NET
L'estrazione di testo da un documento PDF è un'attività comune per gli sviluppatori C# e VB.NET. Puoi usare la libreria Docotic.Pdf per estrarre il testo in poche righe di codice su Windows, Linux, macOS, Android, iOS o in un ambiente cloud.
Per provare il codice di esempio ti serve la libreria Docotic.Pdf. Ottieni la libreria e una chiave di licenza gratuita a tempo limitato nella pagina Scarica la libreria PDF C# .NET.
Esistono diversi approcci all'estrazione del testo. Vediamo alcuni esempi pratici.

Convertire PDF in testo semplice
Puoi usare il testo semplice per l'indicizzazione, la lettura o per qualche tipo di analisi del contenuto PDF. Questo esempio mostra come convertire un PDF in testo in C#:
using BitMiracle.Docotic.Pdf;
using var pdf = new PdfDocument("your_document.pdf");
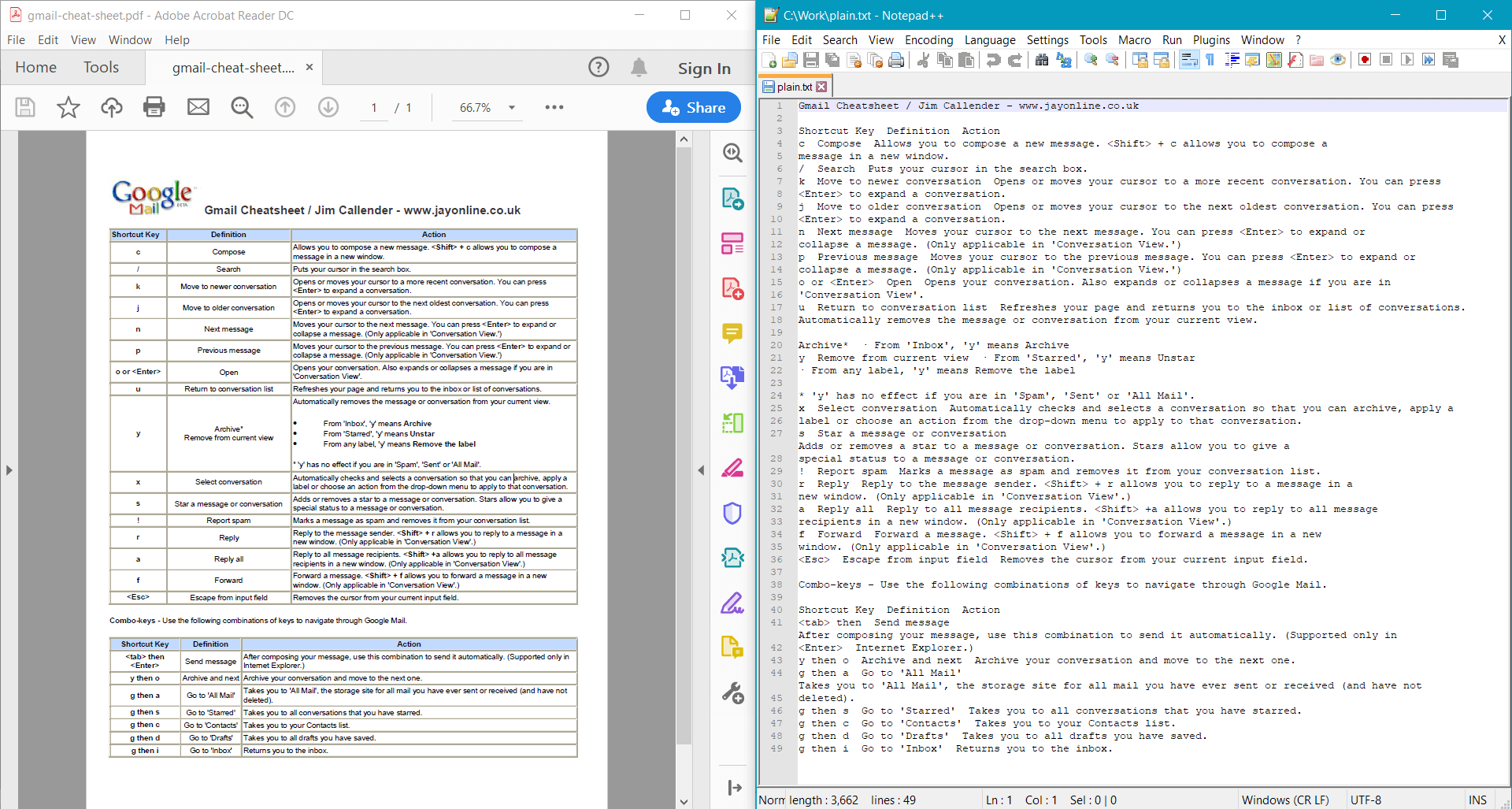
string documentText = pdf.GetText();
Console.WriteLine(documentText);
PdfDocument.GetText() fornisce il seguente risultato per il documento di esempio:
In alternativa, puoi estrarre il testo dalle singole pagine:
using var pdf = new PdfDocument("your_document.pdf");
for (int i = 0; i < pdf.PageCount; ++i)
{
string pageText = pdf.Pages[i].GetText();
using var writer = new StreamWriter($"page_{i}.txt");
writer.Write(pageText);
}
Sono disponibili esempi correlati in C# e VB.NET su GitHub.
Convertire PDF in testo formattato
Puoi usare il testo formattato per analizzare alcuni dati di testo strutturati o per visualizzare il testo in un formato leggibile. Questo esempio mostra come convertire un PDF in testo formattato in C#:
using var pdf = new PdfDocument("your_document.pdf");
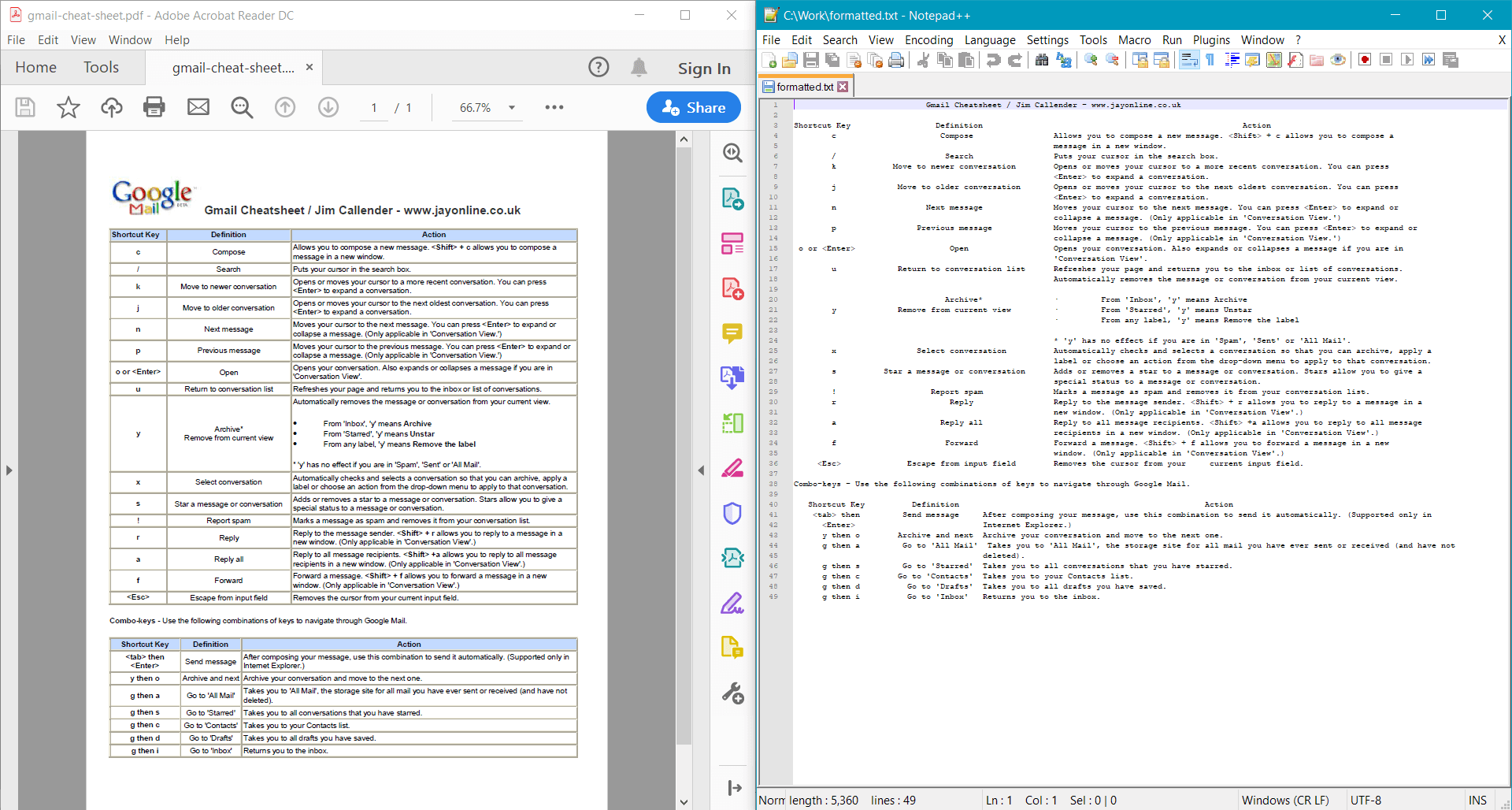
string formattedText = pdf.GetTextWithFormatting();
// un approccio alternativo per pagina
_ = pdf.Pages[0].GetTextWithFormatting();
Console.WriteLine(formattedText);
PdfDocument.GetTextWithFormatting() fornisce il seguente risultato per il documento di esempio:
Estrarre testo semplice o formattato da un'area specifica
Potresti dover estrarre il testo solo da una parte specifica di una pagina PDF. Ad esempio, per analizzare solo il testo nell'intestazione della pagina. Anche questo è supportato dalla libreria. Esempio in C#:
using var pdf = new PdfDocument("your_document.pdf");
var page = pdf.Pages[0];
var options = new PdfTextExtractionOptions
{
Rectangle = new PdfRectangle(0, 0, page.Width, 100),
WithFormatting = false
};
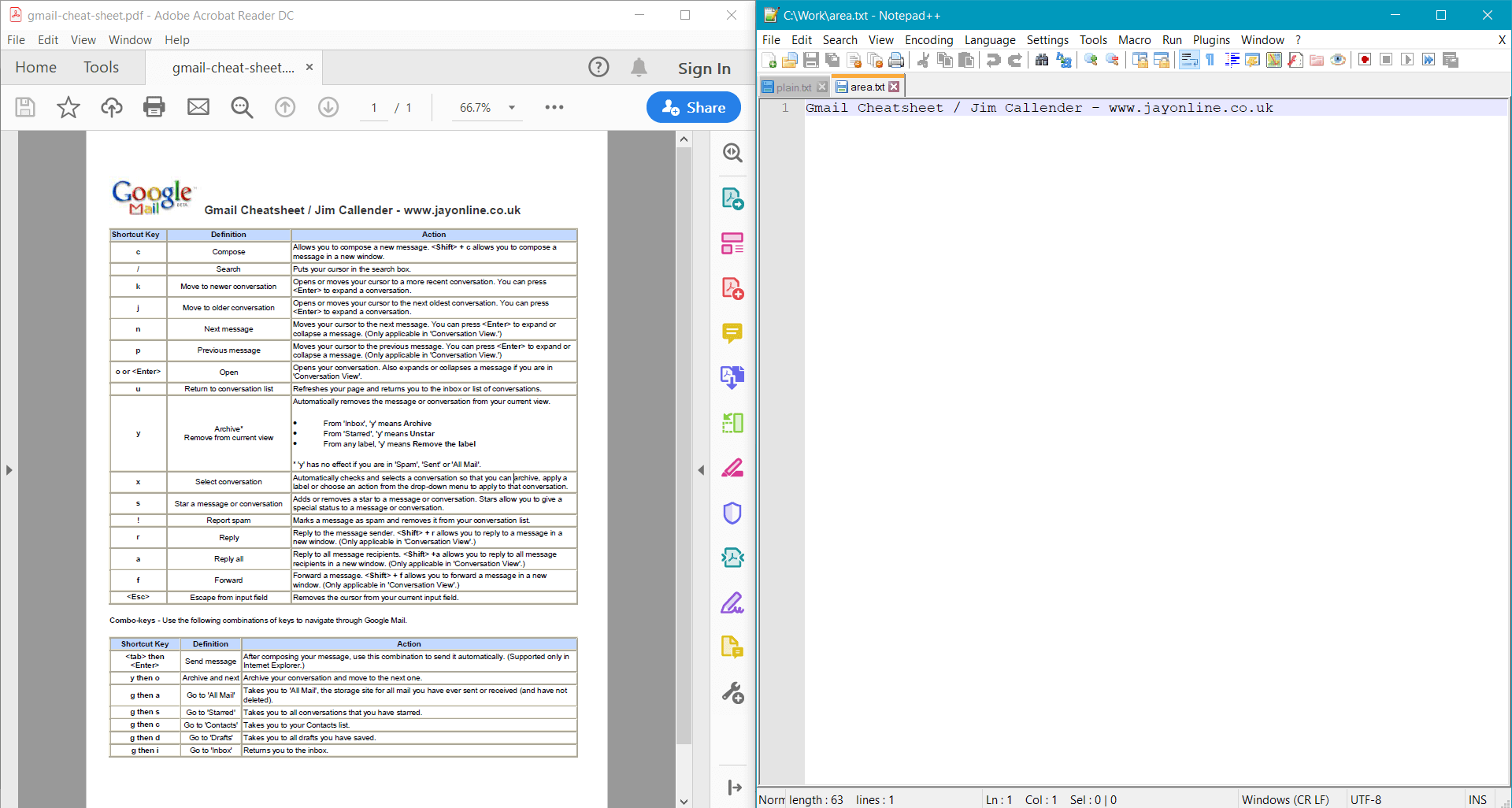
string areaText = page.GetText(options);
Console.WriteLine(areaText);
Questo esempio fornisce il seguente risultato per il documento di esempio:
Estrarre informazioni dettagliate sul testo
Puoi anche ottenere informazioni dettagliate su ogni blocco di testo per un'analisi completa. Docotic.Pdf fornisce metodi per estrarre il testo così com'è, per parole o per caratteri. Per ogni blocco di testo, la libreria estrae:
- Testo Unicode
- Bounding box sulla pagina
- Font
- Dimensione del font
- Matrice di trasformazione, utile per testo scalato e ruotato
- Modalità di rendering
- Colore di riempimento, opacità, motivo
- Stile del contorno
- Informazioni dettagliate su ogni carattere
Questo esempio mostra come estrarre il testo per parole da una pagina PDF in C#:
using var pdf = new PdfDocument("your_document.pdf");
PdfPage page = pdf.Pages[0];
foreach (PdfTextData data in page.GetWords())
{
Console.WriteLine(
$"{{\n" +
$" text: '{data.GetText()}',\n" +
$" bounds: {data.Bounds},\n" +
$" font name: '{data.Font.Name}',\n" +
$" font size: {data.FontSize},\n" +
$" transformation matrix: {data.TransformationMatrix},\n" +
$" rendering mode: '{data.RenderingMode}',\n" +
$" brush: {data.Brush},\n" +
$" pen: {data.Pen}\n" +
$"}},"
);
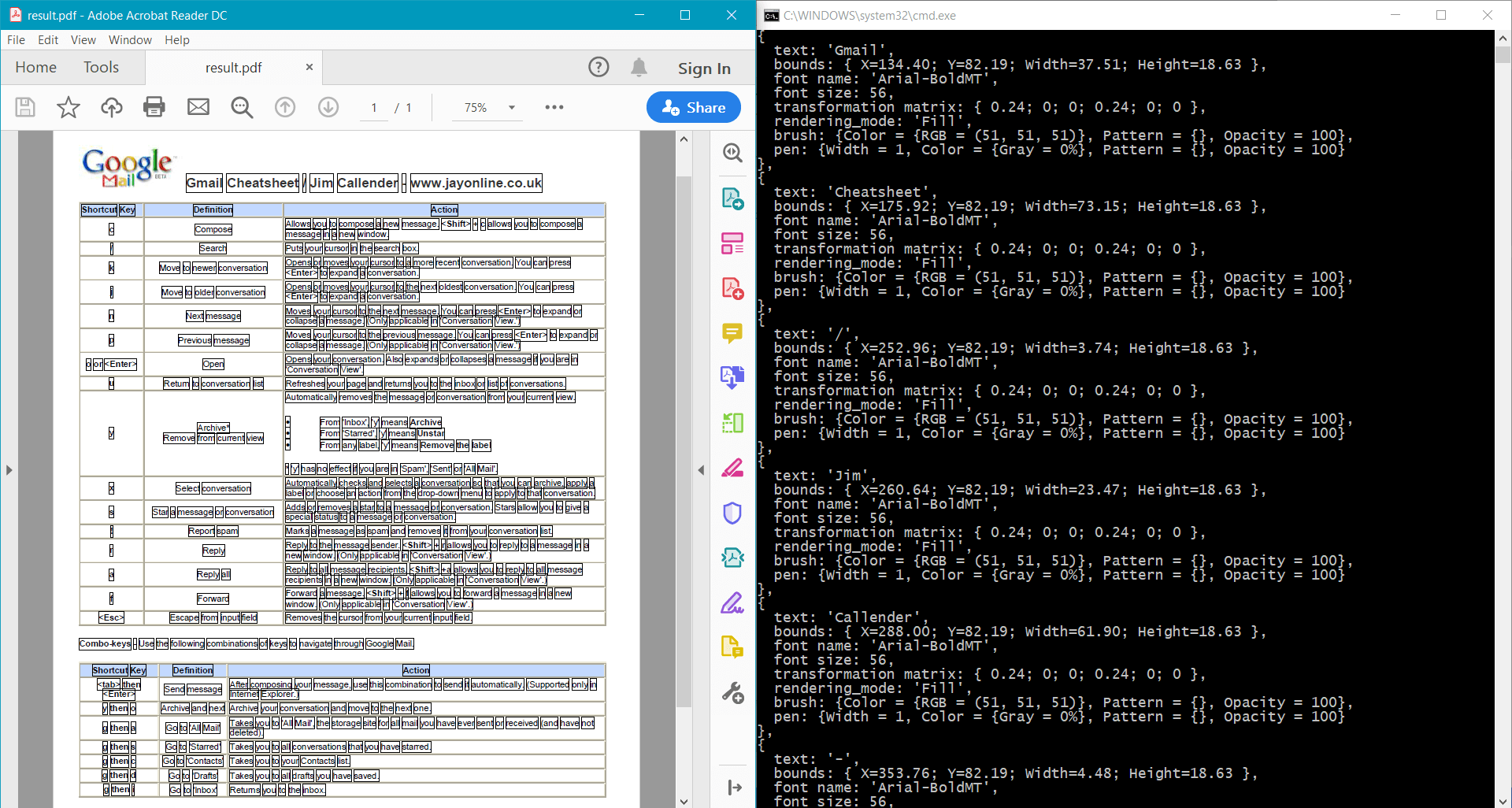
page.Canvas.DrawRectangle(data.Bounds);
}
pdf.Save("result.pdf");
L'esempio fornisce il seguente risultato per il documento di esempio:
Puoi usare i seguenti metodi di Docotic.Pdf per ottenere informazioni dettagliate sul testo:
- PdfCanvas.GetTextData() (ad es. page.Canvas.GetTextData())
- PdfPage.GetWords()
- PdfPage.GetChars()
- PdfPage.GetObjects() (restituisce non solo testo, ma anche immagini e tracciati vettoriali)
Esempi GitHub correlati:
- Estrarre testo per parole
- Trovare ed evidenziare testo
- Estrarre oggetti della pagina
Estrarre testo da destra a sinistra e bidirezionale
Docotic.Pdf estrae correttamente testo arabo, ebraico e persiano da documenti PDF.
Internamente, i documenti PDF memorizzano il testo secondo l'ordine visivo. Ciò significa che il testo nelle lingue con scrittura da destra a sinistra viene memorizzato al contrario. Docotic.Pdf riordina il testo estratto secondo il suo ordine logico. È ciò che di solito si aspettano i lettori di testo da destra a sinistra.
Non devi fare nulla di speciale. Ti basta usare i frammenti di codice sopra per ottenere il testo RTL nell'ordine corretto.
OCR (riconoscimento del testo)
Se i PDF con cui lavori contengono immagini con testo, puoi estrarre il testo usando il riconoscimento ottico dei caratteri. I seguenti esempi mostrano come farlo usando Docotic.Pdf e Tesseract:
- OCR di PDF ed estrazione del testo
- OCR di PDF e conversione in documento ricercabile
Consulta l'articolo OCR PDF in .NET per maggiori dettagli.
Caricamento dei font negli ambienti cloud
Gli esempi sopra funzionano bene in qualsiasi ambiente - su Windows, Linux, macOS. Su piattaforme cloud, come AWS Lambda, potrebbe essere necessario eseguire un ulteriore passaggio di configurazione.
Esistono documenti PDF che usano font non incorporati. Per impostazione predefinita, Docotic.Pdf carica questi font dalla raccolta di font di sistema (ad es. C:/Windows/Fonts o /usr/share/fonts). Tuttavia, le piattaforme cloud possono limitare l'accesso a queste raccolte di font.
Puoi distribuire con la tua applicazione una raccolta di font comuni. Trova e copia i file di font pubblici nel tuo progetto. Imposta tutti i file di font con CopyToOutputDirectory = Always nel tuo progetto .NET. Per usare la raccolta, inizializza PdfDocument con un DirectoryFontLoader personalizzato:
PdfConfigurationOptions config = PdfConfigurationOptions.Create();
config.FontLoader = new DirectoryFontLoader(["path_to_your_font_collection"], true);
using var pdf = new PdfDocument("your_document.pdf", config);
// ...
Conclusione
Puoi usare la libreria Docotic.Pdf per estrarre testo semplice o formattato da PDF in C# e VB.NET. Puoi anche estrarre informazioni dettagliate su ogni blocco di testo. Puoi scaricare Docotic.Pdf qui.
Guarda gli esempi in C# e VB.NET per estrarre testo da PDF: