該頁面可以包含自動翻譯的文字。
在 C# 和 VB.NET 中從 PDF 擷取文字
從 PDF 文件擷取文字是 C# 和 VB.NET 開發人員常見的工作。您可以使用 Docotic.Pdf 程式庫 在 Windows、Linux、macOS、Android、iOS 或雲端環境中,只需幾行程式碼即可擷取文字。
您需要 Docotic.Pdf 程式庫才能試用範例程式碼。請到 下載 C# .NET PDF 程式庫 頁面取得程式庫和免費的限時授權金鑰。
文字擷取有不同的方法。讓我們看看一些實用範例。

將 PDF 轉換為純文字
您可以將純文字用於索引、閱讀,或對 PDF 內容進行某種分析。此範例示範如何在 C# 中將 PDF 轉換為文字:
using BitMiracle.Docotic.Pdf;
using var pdf = new PdfDocument("your_document.pdf");
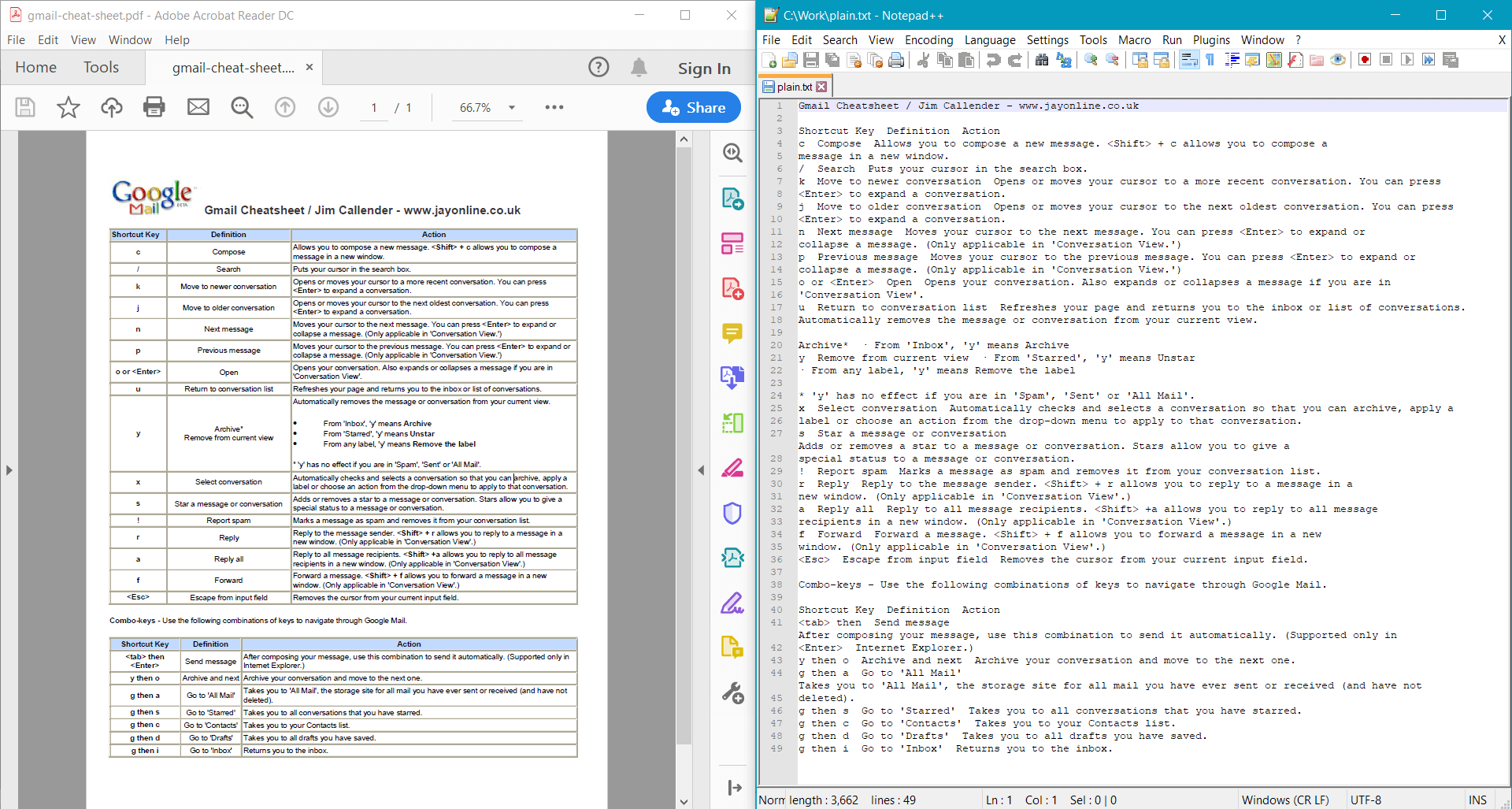
string documentText = pdf.GetText();
Console.WriteLine(documentText);
PdfDocument.GetText() 提供了 範例文件 的以下結果:
或者,您可以從個別頁面擷取文字:
using var pdf = new PdfDocument("your_document.pdf");
for (int i = 0; i < pdf.PageCount; ++i)
{
string pageText = pdf.Pages[i].GetText();
using var writer = new StreamWriter($"page_{i}.txt");
writer.Write(pageText);
}
相關的 C# 和 VB.NET 範例可在 GitHub 上 取得。
將 PDF 轉換為格式化文字
您可以使用格式化文字來解析某些結構化文字資料,或以易於閱讀的格式顯示文字。此範例示範如何在 C# 中將 PDF 轉換為格式化文字:
using var pdf = new PdfDocument("your_document.pdf");
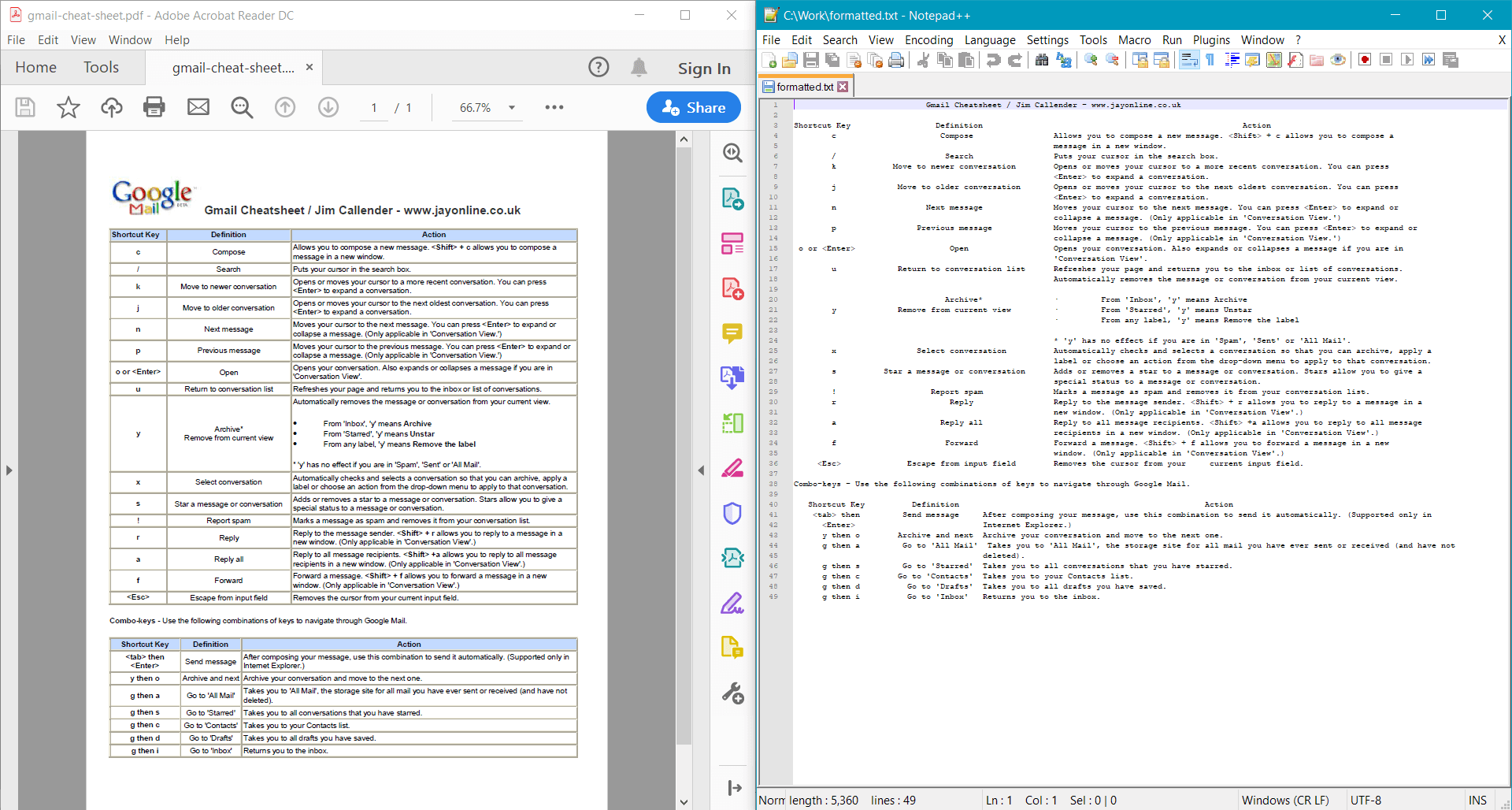
string formattedText = pdf.GetTextWithFormatting();
// 每頁的替代方法
_ = pdf.Pages[0].GetTextWithFormatting();
Console.WriteLine(formattedText);
PdfDocument.GetTextWithFormatting() 提供了 範例文件 的以下結果:
從特定區域擷取純文字或格式化文字
您可能只需要從 PDF 頁面的特定部分擷取文字。例如,只解析頁首中的文字。此程式庫也支援這項功能。C# 範例:
using var pdf = new PdfDocument("your_document.pdf");
var page = pdf.Pages[0];
var options = new PdfTextExtractionOptions
{
Rectangle = new PdfRectangle(0, 0, page.Width, 100),
WithFormatting = false
};
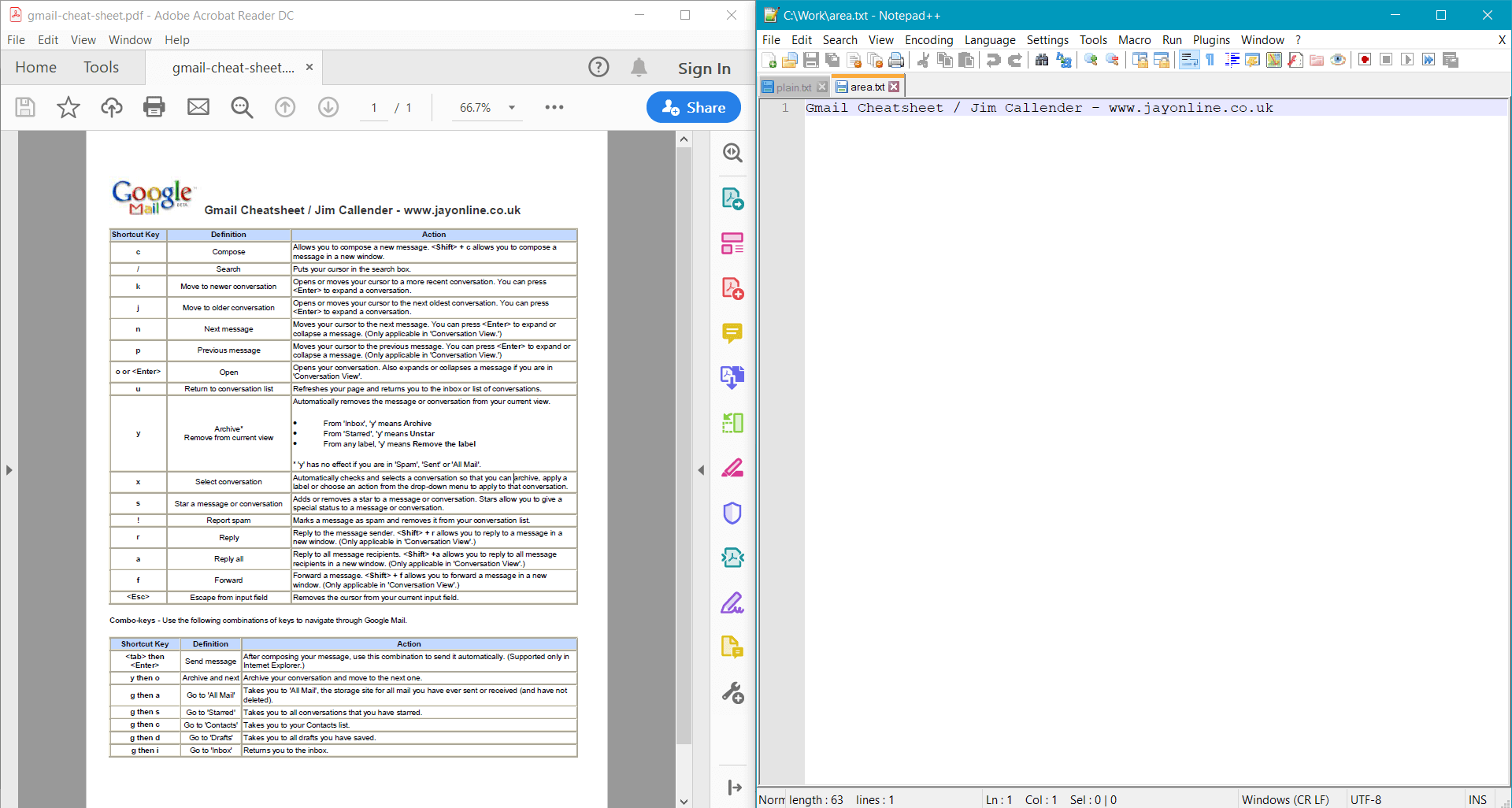
string areaText = page.GetText(options);
Console.WriteLine(areaText);
此範例提供了 範例文件 的以下結果:
擷取詳細文字資訊
您也可以取得每個文字區塊的詳細資訊,以進行完整分析。Docotic.Pdf 提供依原樣、按字詞或按字元擷取文字的方法。對於每個文字區塊,程式庫會擷取:
- Unicode 文字
- 頁面上的邊界
- 字型
- 字型大小
- 變換矩陣,這對縮放與旋轉文字很有用
- 繪製模式
- 填滿色彩、不透明度、圖樣
- 外框樣式
- 每個字元的詳細資訊
此範例示範如何在 C# 中從 PDF 頁面按字詞擷取文字:
using var pdf = new PdfDocument("your_document.pdf");
PdfPage page = pdf.Pages[0];
foreach (PdfTextData data in page.GetWords())
{
Console.WriteLine(
$"{{\n" +
$" text: '{data.GetText()}',\n" +
$" bounds: {data.Bounds},\n" +
$" font name: '{data.Font.Name}',\n" +
$" font size: {data.FontSize},\n" +
$" transformation matrix: {data.TransformationMatrix},\n" +
$" rendering mode: '{data.RenderingMode}',\n" +
$" brush: {data.Brush},\n" +
$" pen: {data.Pen}\n" +
$"}},"
);
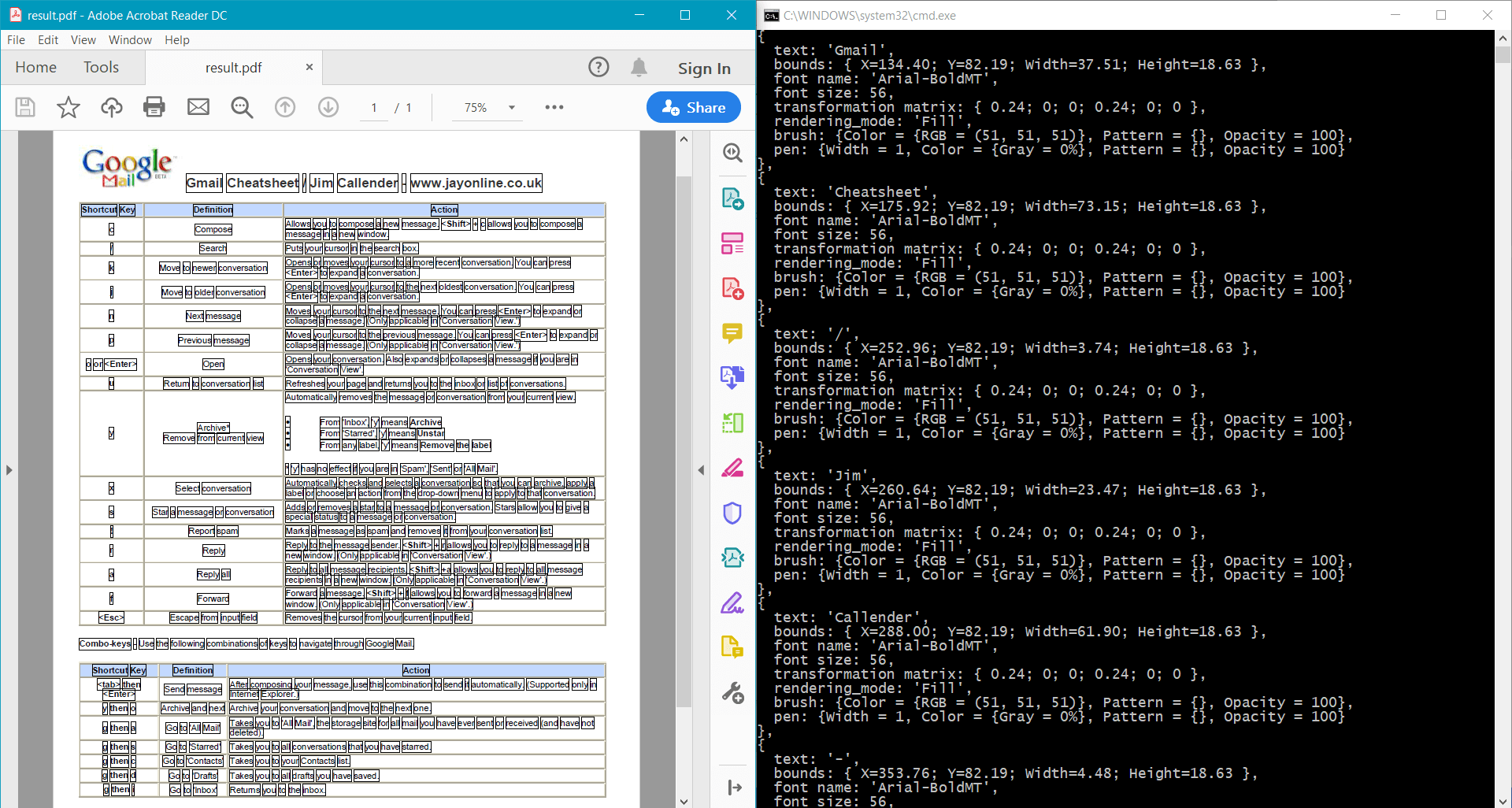
page.Canvas.DrawRectangle(data.Bounds);
}
pdf.Save("result.pdf");
此範例為 範例文件 提供了以下結果:
您可以使用以下 Docotic.Pdf 方法取得詳細文字資訊:
- PdfCanvas.GetTextData()(例如 page.Canvas.GetTextData())
- PdfPage.GetWords()
- PdfPage.GetChars()
- PdfPage.GetObjects()(不僅會回傳文字,也會回傳圖片和向量路徑)
相關 GitHub 範例:
Docotic.Pdf 可以正確擷取 PDF 文件中的阿拉伯文、希伯來文和波斯文文字。
在內部,PDF 文件會依照視覺順序儲存文字。這表示使用從右至左書寫系統的語言文字會以反向方式儲存。Docotic.Pdf 會依照邏輯順序重新排序擷取出的文字。這通常也是從右至左文字讀者所期望的行為。
您不需要做任何特殊處理。只要使用上面的程式碼片段,就能以正確順序取得 RTL 文字。
OCR(文字辨識)
如果您處理的 PDF 中包含帶有文字的圖片,則可以使用光學字元辨識來擷取文字。下列範例示範如何使用 Docotic.Pdf 和 Tesseract 來完成:
- OCR PDF 並擷取文字
- OCR PDF 並轉換為可搜尋文件
請參閱 在 .NET 中對 PDF 進行 OCR 文章以了解更多細節。
雲端環境中的字型載入
上面的範例在任何環境中都能正常運作——在 Windows、Linux、macOS 上也是如此。在 AWS Lambda 等雲端平台上,您可能需要再做一個額外的設定步驟。
有些 PDF 文件使用未嵌入字型。預設情況下,Docotic.Pdf 會從系統字型集合(例如 C:/Windows/Fonts 或 /usr/share/fonts)載入這類字型。不過,雲端平台可能會限制對這些字型集合的存取。
您可以隨應用程式部署自己的常用字型集合。尋找並複製公開的字型檔案到您的專案中。在您的 .NET 專案中,將所有字型檔案標記為 CopyToOutputDirectory = Always。若要使用該集合,請以自訂的 DirectoryFontLoader 初始化 PdfDocument:
PdfConfigurationOptions config = PdfConfigurationOptions.Create();
config.FontLoader = new DirectoryFontLoader(["path_to_your_font_collection"], true);
using var pdf = new PdfDocument("your_document.pdf", config);
// ...
結論
您可以使用 Docotic.Pdf 程式庫 在 C# 和 VB.NET 中從 PDF 擷取純文字或格式化文字。您也可以擷取每個文字區塊的詳細資訊。您可以在 這裡 下載 Docotic.Pdf。
查看下列用於從 PDF 擷取文字的 C# 和 VB.NET 範例: