Эта страница может содержать автоматически переведенный текст.
Извлечение текста из PDF в C# и VB.NET
Извлечение текста из PDF-документа — распространенная задача для разработчиков C# и VB.NET. Вы можете использовать библиотеку Docotic.Pdf для извлечения текста всего в нескольких строках кода в Windows, Linux, macOS, Android, iOS или в облачной среде.
Для проверки примера потребуется библиотека Docotic.Pdf. Получите библиотеку и бесплатный временный ключ лицензии на странице Скачать C# .NET библиотеку PDF.
Существуют разные подходы к извлечению текста. Рассмотрим несколько практических примеров.

Преобразование PDF в обычный текст
Вы можете использовать обычный текст для индексирования, чтения или некоторого анализа содержимого PDF. Этот пример показывает, как преобразовать PDF в текст в C#:
using BitMiracle.Docotic.Pdf;
using var pdf = new PdfDocument("your_document.pdf");
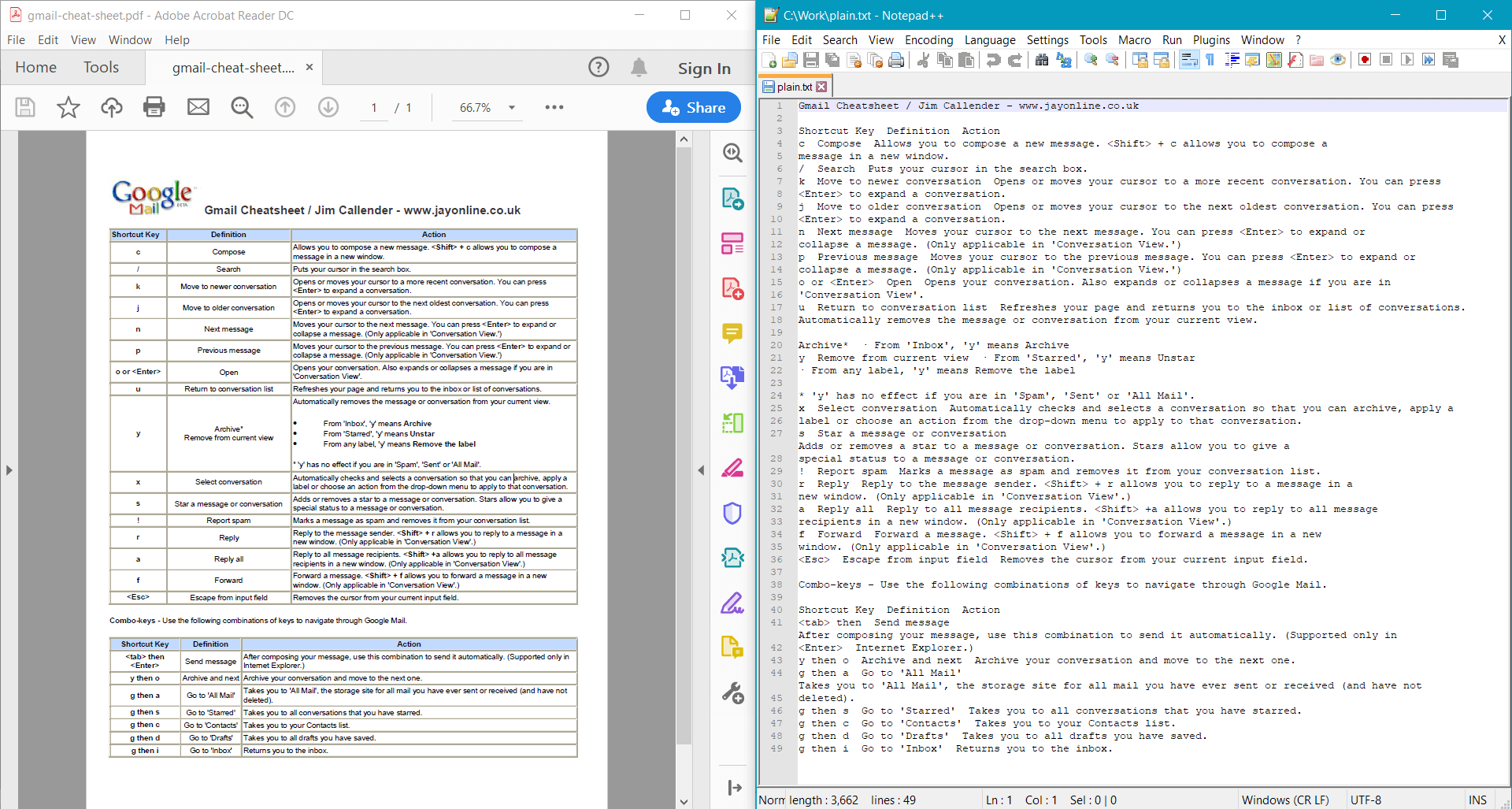
string documentText = pdf.GetText();
Console.WriteLine(documentText);
PdfDocument.GetText() возвращает следующий результат для образца документа:
Кроме того, можно извлекать текст из отдельных страниц:
using var pdf = new PdfDocument("your_document.pdf");
for (int i = 0; i < pdf.PageCount; ++i)
{
string pageText = pdf.Pages[i].GetText();
using var writer = new StreamWriter($"page_{i}.txt");
writer.Write(pageText);
}
Связанные примеры для C# и VB.NET доступны на GitHub.
Преобразование PDF в форматированный текст
Вы можете использовать форматированный текст для разбора некоторых структурированных текстовых данных или для отображения текста в удобочитаемом формате. Этот пример показывает, как преобразовать PDF в форматированный текст в C#:
using var pdf = new PdfDocument("your_document.pdf");
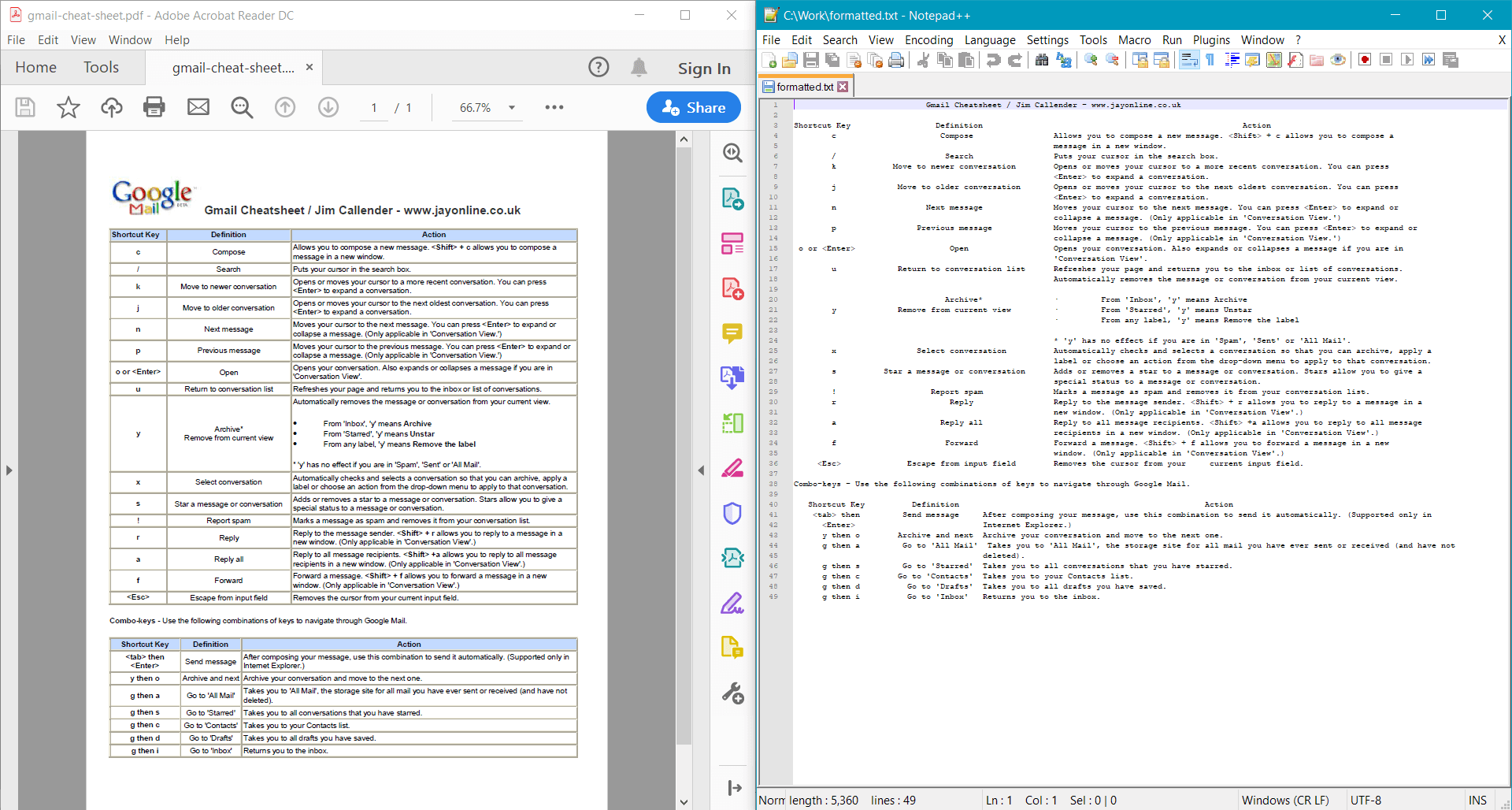
string formattedText = pdf.GetTextWithFormatting();
// альтернативный подход для обработки по страницам
_ = pdf.Pages[0].GetTextWithFormatting();
Console.WriteLine(formattedText);
PdfDocument.GetTextWithFormatting() возвращает следующий результат для образца документа:
Извлечение обычного или форматированного текста из определенной области
Возможно, вам нужно извлечь текст только из определенной части страницы PDF. Например, только разобрать текст в верхнем колонтитуле страницы. Библиотека также поддерживает это. Пример на C#:
using var pdf = new PdfDocument("your_document.pdf");
var page = pdf.Pages[0];
var options = new PdfTextExtractionOptions
{
Rectangle = new PdfRectangle(0, 0, page.Width, 100),
WithFormatting = false
};
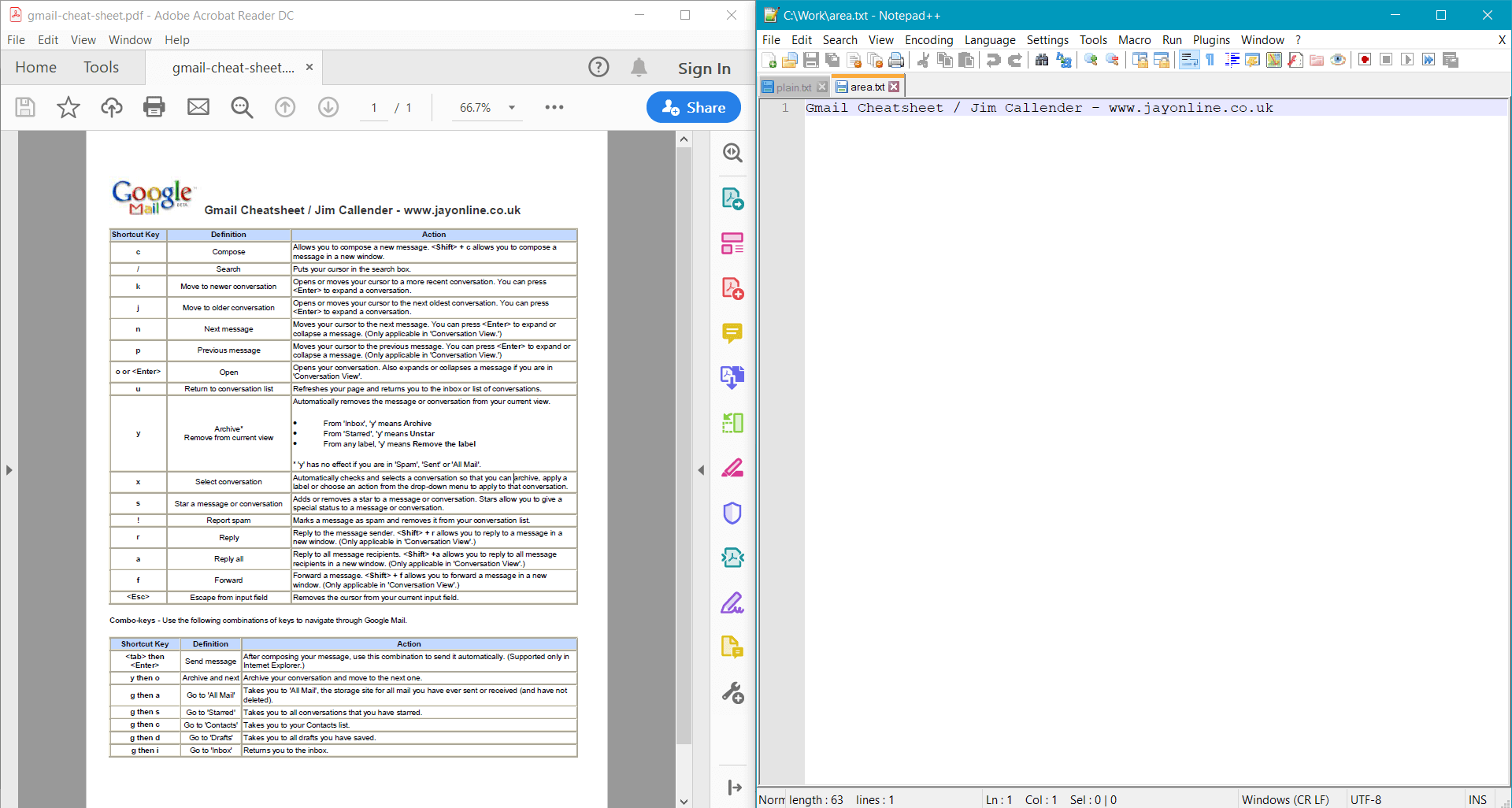
string areaText = page.GetText(options);
Console.WriteLine(areaText);
Этот пример возвращает следующий результат для образца документа:
Извлечение подробной текстовой информации
Вы также можете получить подробную информацию о каждом фрагменте текста для всестороннего анализа. Docotic.Pdf предоставляет методы для извлечения текста как есть, по словам или по символам. Для каждого фрагмента текста библиотека извлекает:
- Текст Unicode
- Границы на странице
- Шрифт
- Размер шрифта
- Матрица преобразования, которая полезна для масштабированного и повернутого текста
- Режим отображения
- Цвет заливки, непрозрачность, шаблон
- Стиль контура
- Подробная информация о каждом символе
Этот пример показывает, как извлечь текст по словам со страницы PDF в C#:
using var pdf = new PdfDocument("your_document.pdf");
PdfPage page = pdf.Pages[0];
foreach (PdfTextData data in page.GetWords())
{
Console.WriteLine(
$"{{\n" +
$" text: '{data.GetText()}',\n" +
$" bounds: {data.Bounds},\n" +
$" font name: '{data.Font.Name}',\n" +
$" font size: {data.FontSize},\n" +
$" transformation matrix: {data.TransformationMatrix},\n" +
$" rendering mode: '{data.RenderingMode}',\n" +
$" brush: {data.Brush},\n" +
$" pen: {data.Pen}\n" +
$"}},"
);
page.Canvas.DrawRectangle(data.Bounds);
}
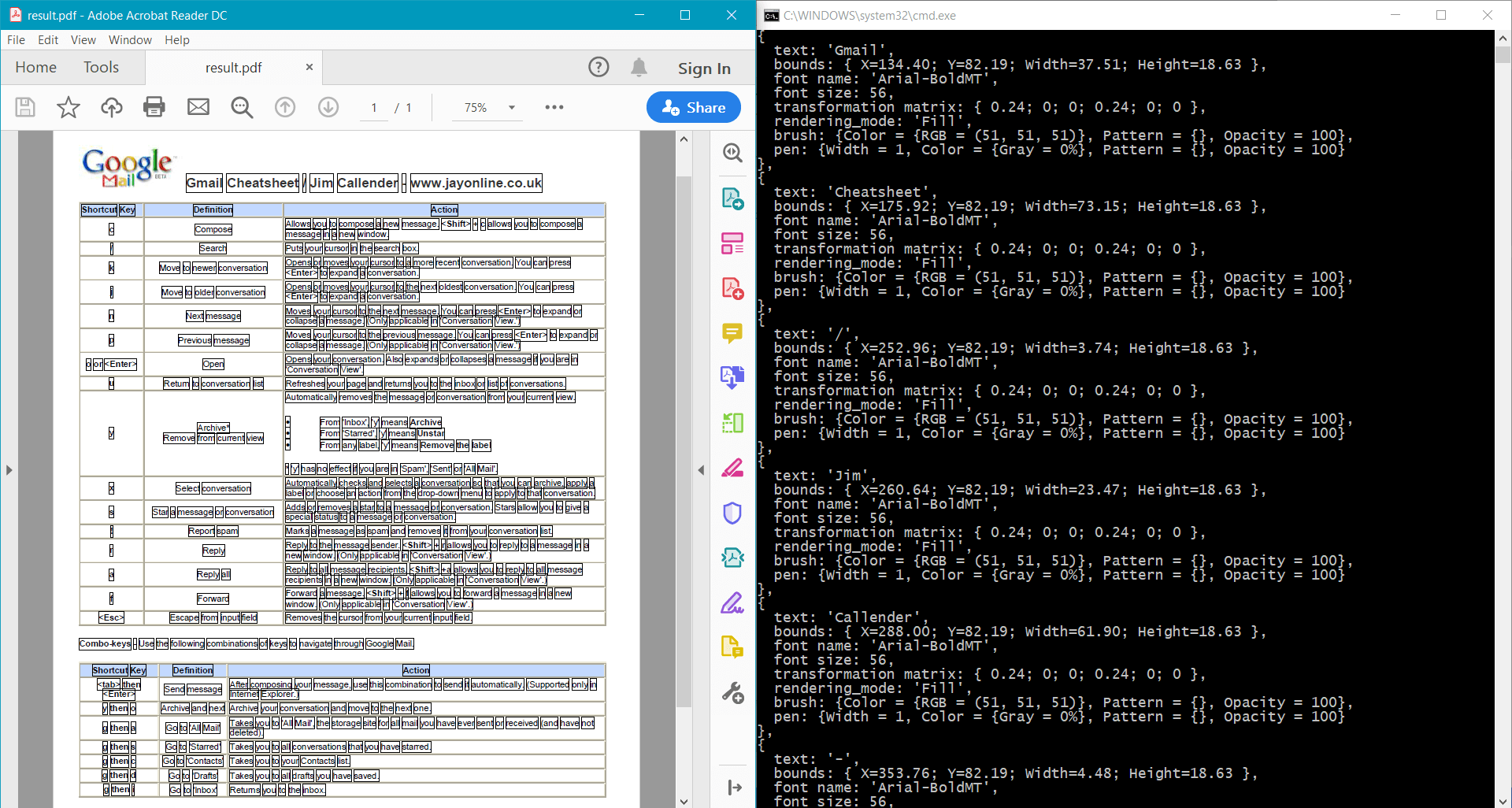
pdf.Save("result.pdf");
Этот пример возвращает следующий результат для образца документа:
Вы можете использовать следующие методы Docotic.Pdf для получения подробной текстовой информации:
- PdfCanvas.GetTextData() (например, page.Canvas.GetTextData())
- PdfPage.GetWords()
- PdfPage.GetChars()
- PdfPage.GetObjects() (возвращает не только текст, но и изображения и векторные контуры тоже)
Связанные примеры на GitHub:
- Извлечение текста по словам
- Поиск текста и выделение
- Извлечение объектов страницы
Извлечение текста справа налево и двунаправленного текста
Docotic.Pdf корректно извлекает арабский, ивритский и персидский текст из PDF-документов.
Внутри PDF-документы хранят текст в соответствии с визуальным порядком. Это означает, что текст на языках с письмом справа налево хранится в перевернутом виде. Docotic.Pdf перестраивает извлеченный текст в соответствии с его логическим порядком. Именно этого обычно ожидают читатели текста справа налево.
Вам не нужно делать ничего особенного. Просто используйте приведенные выше фрагменты кода, чтобы получить текст RTL в правильном порядке.
OCR (распознавание текста)
Если PDF, с которыми вы работаете, содержат изображения с текстом, вы можете извлечь текст с помощью оптического распознавания символов. Следующие примеры показывают, как это сделать с помощью Docotic.Pdf и Tesseract:
- OCR PDF и извлечение текста
- OCR PDF и преобразование в документ с возможностью поиска
Подробности см. в статье OCR PDF in .NET.
Загрузка шрифтов в облачных средах
Приведенные выше примеры хорошо работают в любой среде — на Windows, Linux, macOS. В облачных платформах, таких как AWS Lambda, может потребоваться выполнить еще один шаг настройки.
Существуют PDF-документы, использующие невстроенные шрифты. По умолчанию Docotic.Pdf загружает такие шрифты из системной коллекции шрифтов (например, C:/Windows/Fonts или /usr/share/fonts). Однако облачные платформы могут ограничивать доступ к этим коллекциям шрифтов.
Вы можете развернуть собственную коллекцию популярных шрифтов вместе с приложением. Найдите и скопируйте публичные файлы шрифтов в проект. Пометьте все файлы шрифтов значением CopyToOutputDirectory = Always в проекте .NET. Чтобы использовать коллекцию, инициализируйте PdfDocument с пользовательским DirectoryFontLoader:
PdfConfigurationOptions config = PdfConfigurationOptions.Create();
config.FontLoader = new DirectoryFontLoader(["path_to_your_font_collection"], true);
using var pdf = new PdfDocument("your_document.pdf", config);
// ...
Заключение
Вы можете использовать библиотеку Docotic.Pdf для извлечения обычного или форматированного текста из PDF в C# и VB.NET. Вы также можете извлекать подробную информацию о каждом фрагменте текста. Скачать Docotic.Pdf можно здесь.
Посмотрите примеры для C# и VB.NET по извлечению текста из PDF: