Diese Seite kann automatisch übersetzten Text enthalten.
Text aus PDF in C# und VB.NET extrahieren
Das Extrahieren von Text aus einem PDF-Dokument ist eine häufige Aufgabe für C#- und VB.NET-Entwickler. Sie können die Docotic.Pdf-Bibliothek verwenden, um Text in nur wenigen Zeilen Code unter Windows, Linux, macOS, Android, iOS oder in einer Cloud-Umgebung zu extrahieren.
Sie benötigen die Docotic.Pdf-Bibliothek, um den Beispielcode auszuprobieren. Holen Sie sich die Bibliothek und einen kostenlosen zeitlich begrenzten Lizenzschlüssel auf der C# .NET-PDF-Bibliothek herunterladen-Seite.
Es gibt verschiedene Ansätze zur Textextraktion. Sehen wir uns einige praktische Beispiele an.

PDF in Klartext konvertieren
Sie können Klartext für die Indizierung, zum Lesen oder für eine Art der Analyse von PDF-Inhalten verwenden. Dieses Beispiel zeigt, wie Sie PDF in C# in Text konvertieren:
using BitMiracle.Docotic.Pdf;
using var pdf = new PdfDocument("your_document.pdf");
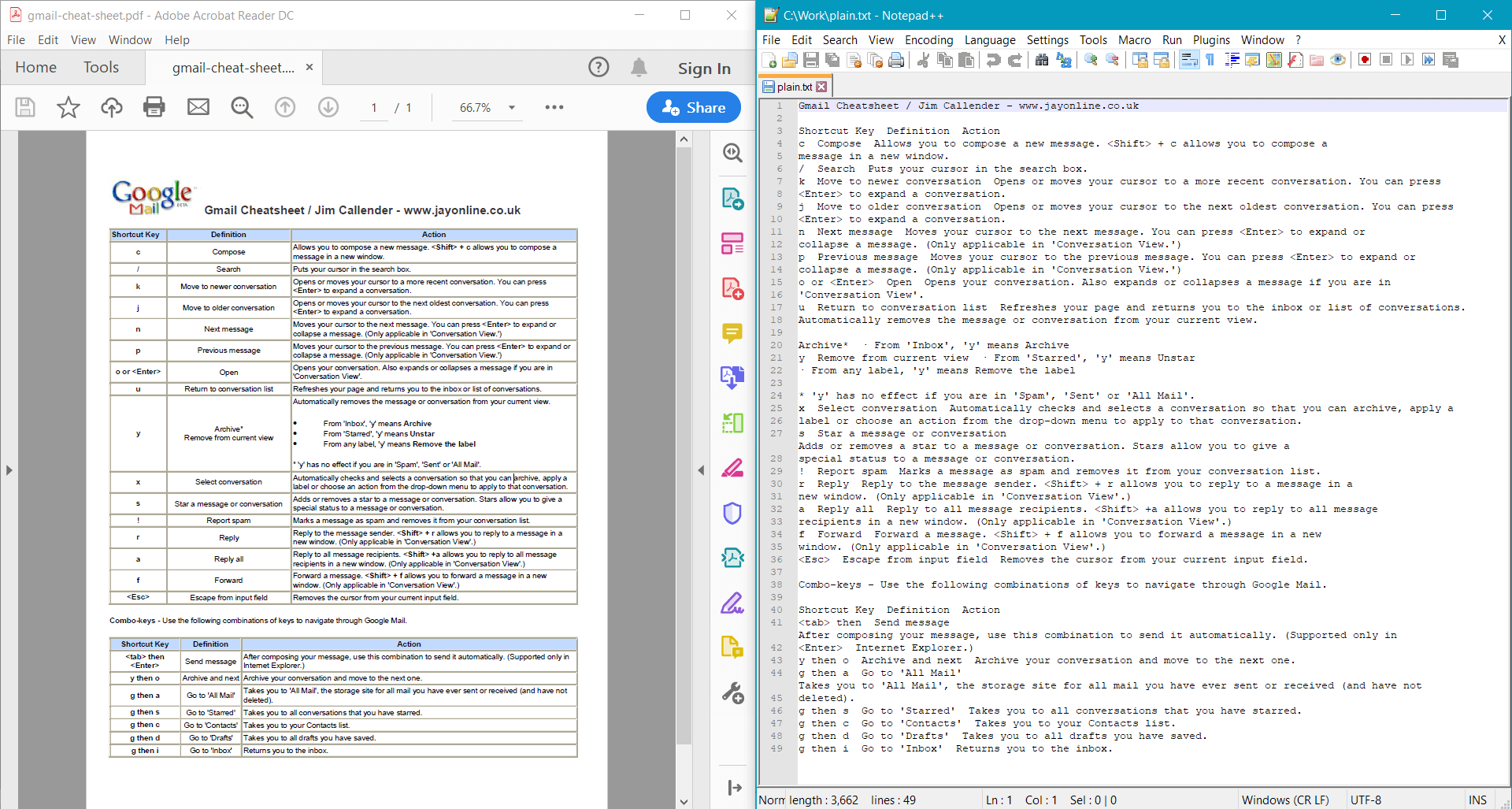
string documentText = pdf.GetText();
Console.WriteLine(documentText);
PdfDocument.GetText() liefert das folgende Ergebnis für das Beispieldokument:
Alternativ können Sie Text aus einzelnen Seiten extrahieren:
using var pdf = new PdfDocument("your_document.pdf");
for (int i = 0; i < pdf.PageCount; ++i)
{
string pageText = pdf.Pages[i].GetText();
using var writer = new StreamWriter($"page_{i}.txt");
writer.Write(pageText);
}
Zugehörige C#- und VB.NET-Beispiele sind auf GitHub verfügbar.
PDF in formatierten Text konvertieren
Sie können formatierten Text verwenden, um einige strukturierte Textdaten zu analysieren oder den Text in einem menschenlesbaren Format anzuzeigen. Dieses Beispiel zeigt, wie Sie PDF in C# in formatierten Text konvertieren:
using var pdf = new PdfDocument("your_document.pdf");
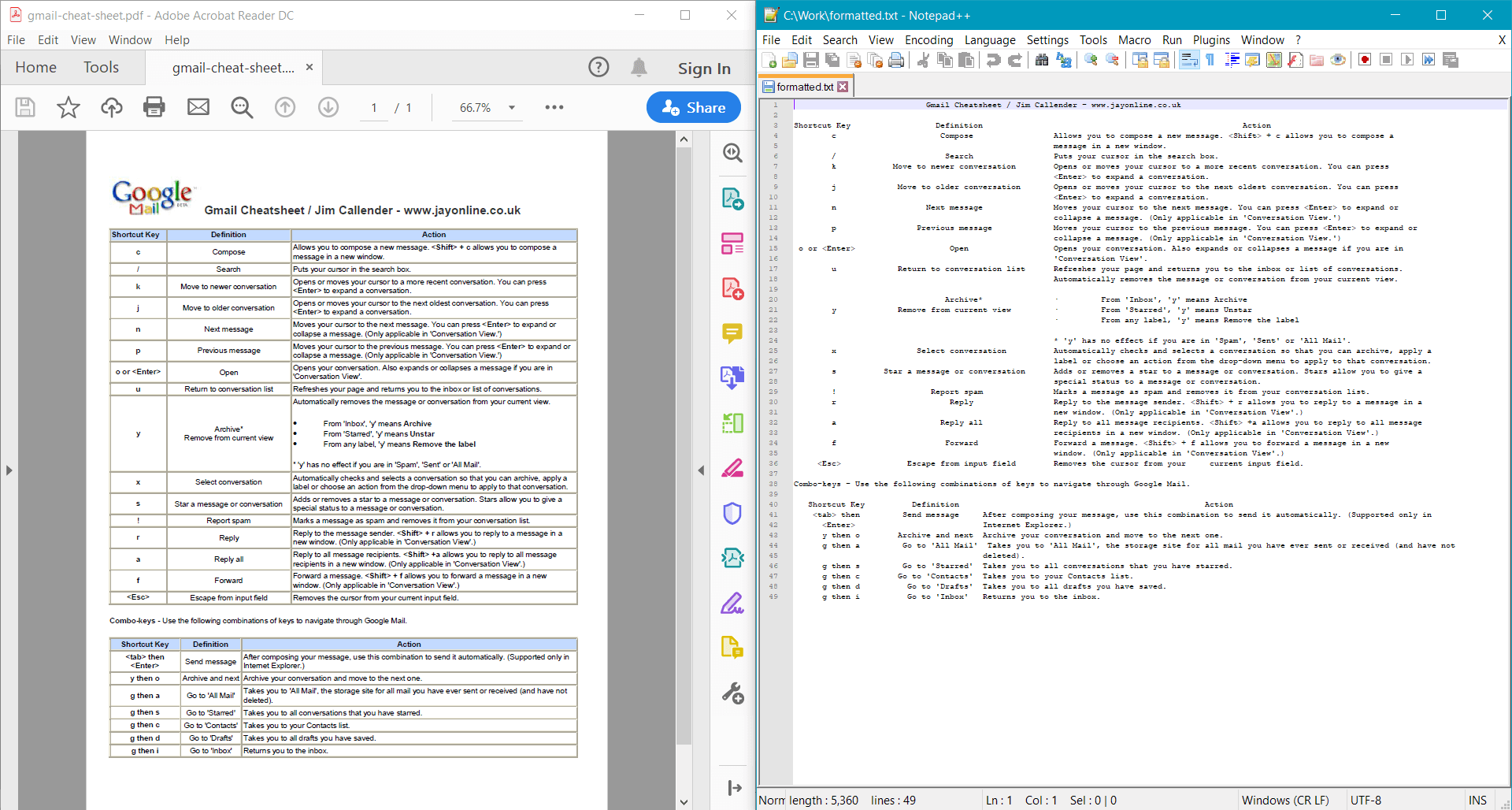
string formattedText = pdf.GetTextWithFormatting();
// ein alternativer seitenweiser Ansatz
_ = pdf.Pages[0].GetTextWithFormatting();
Console.WriteLine(formattedText);
PdfDocument.GetTextWithFormatting() liefert das folgende Ergebnis für das Beispieldokument:
Klartext oder formatierten Text aus einem bestimmten Bereich extrahieren
Möglicherweise müssen Sie Text nur aus einem bestimmten Teil einer PDF-Seite extrahieren. Beispielsweise, um nur den Text im Seitenkopf zu analysieren. Die Bibliothek unterstützt dies ebenfalls. C#-Beispiel:
using var pdf = new PdfDocument("your_document.pdf");
var page = pdf.Pages[0];
var options = new PdfTextExtractionOptions
{
Rectangle = new PdfRectangle(0, 0, page.Width, 100),
WithFormatting = false
};
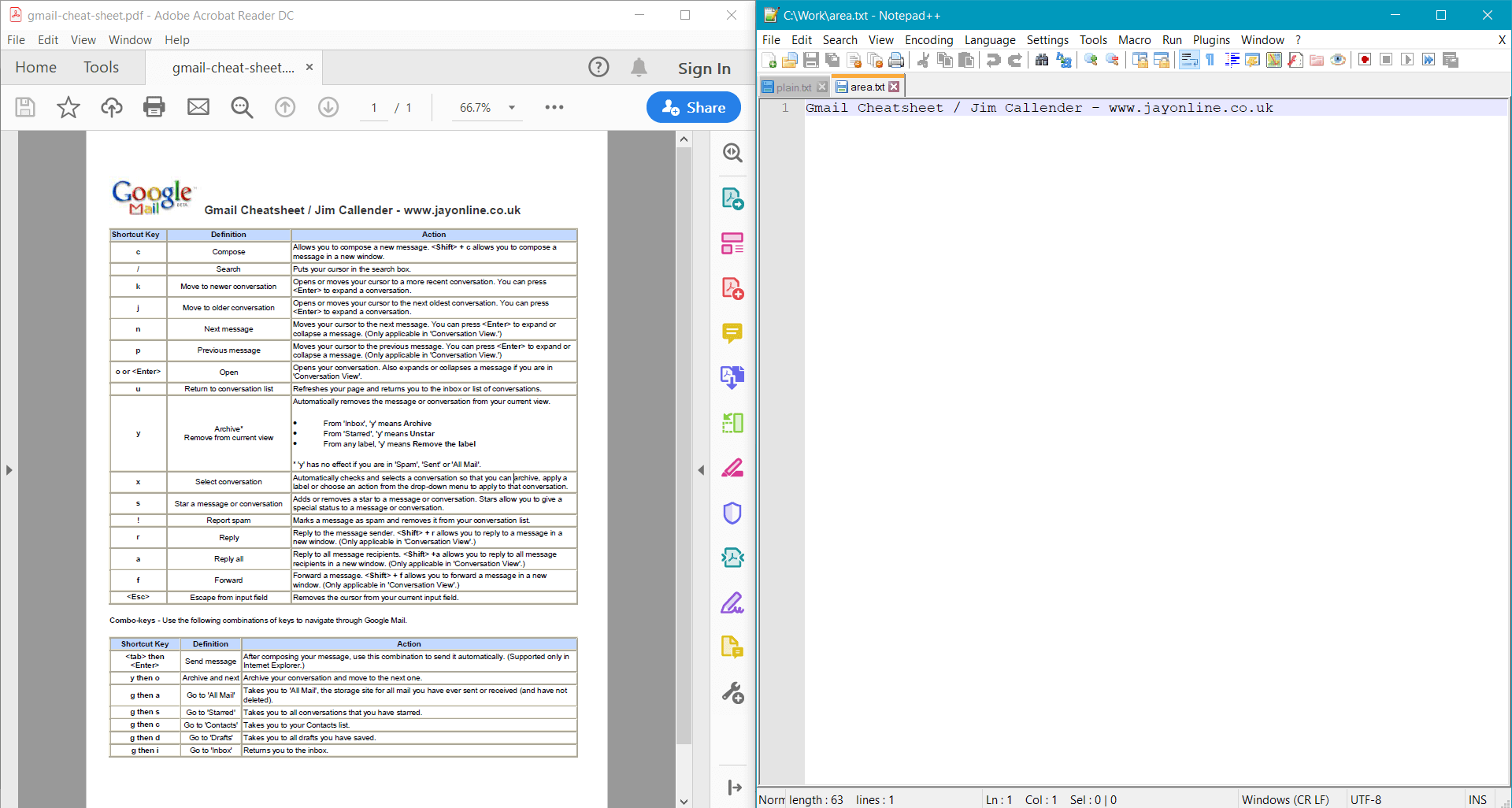
string areaText = page.GetText(options);
Console.WriteLine(areaText);
Dieses Beispiel liefert das folgende Ergebnis für das Beispieldokument:
Detaillierte Textinformationen extrahieren
Sie können auch detaillierte Informationen zu jedem Textabschnitt für eine umfassende Analyse erhalten. Docotic.Pdf bietet Methoden zum Extrahieren von Text unverändert, nach Wörtern oder nach Zeichen. Für jeden Textabschnitt extrahiert die Bibliothek:
- Unicode-Text
- Begrenzungen auf der Seite
- Schriftart
- Schriftgröße
- Transformationsmatrix, die für skalierten und gedrehten Text nützlich ist
- Rendermodus
- Füllfarbe, Deckkraft, Muster
- Konturstil
- Detaillierte Informationen zu jedem Zeichen
Dieses Beispiel zeigt, wie Sie Text nach Wörtern aus einer PDF-Seite in C# extrahieren:
using var pdf = new PdfDocument("your_document.pdf");
PdfPage page = pdf.Pages[0];
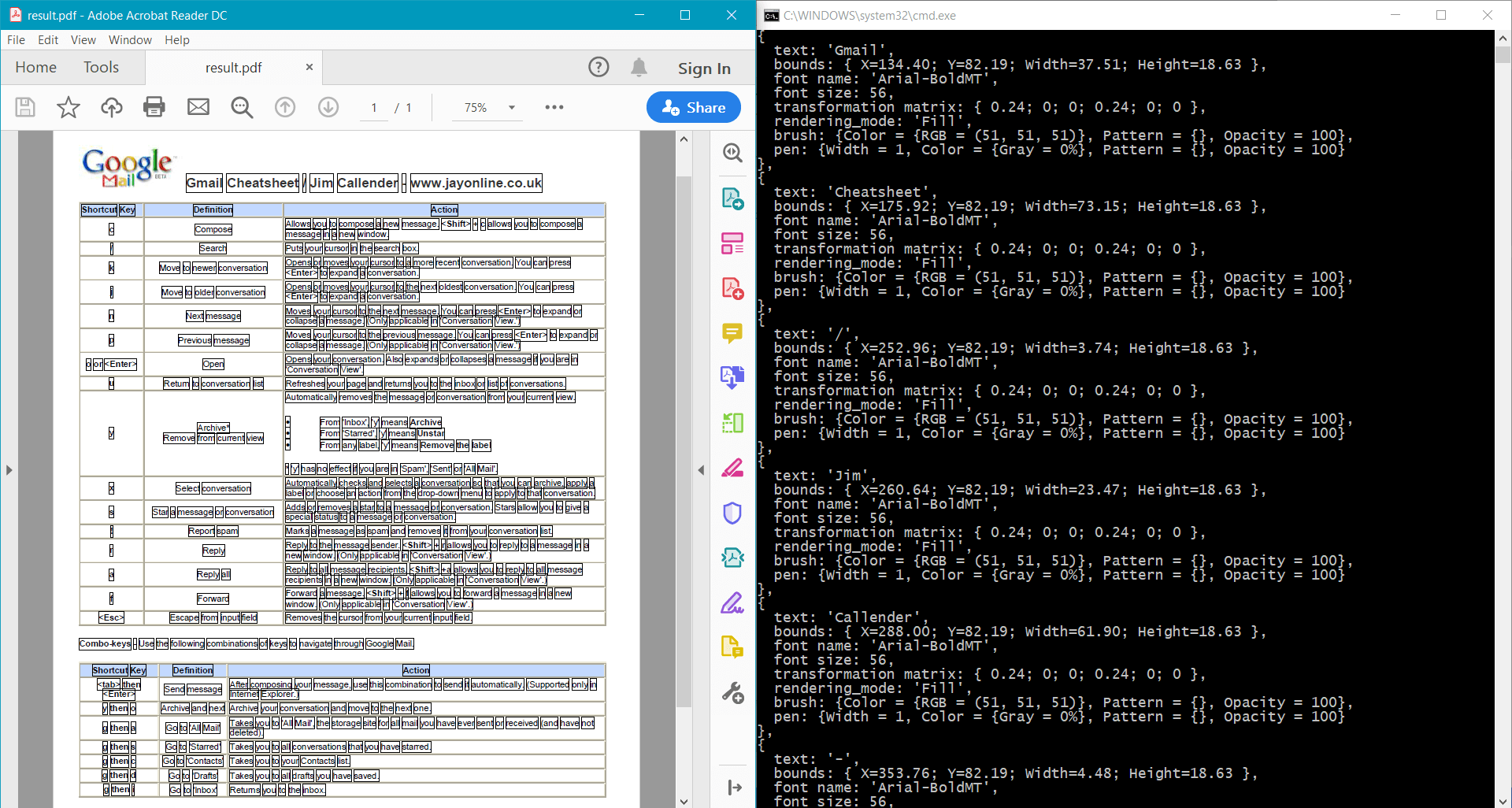
foreach (PdfTextData data in page.GetWords())
{
Console.WriteLine(
$"{{\n" +
$" text: '{data.GetText()}',\n" +
$" bounds: {data.Bounds},\n" +
$" font name: '{data.Font.Name}',\n" +
$" font size: {data.FontSize},\n" +
$" transformation matrix: {data.TransformationMatrix},\n" +
$" rendering mode: '{data.RenderingMode}',\n" +
$" brush: {data.Brush},\n" +
$" pen: {data.Pen}\n" +
$"}},"
);
page.Canvas.DrawRectangle(data.Bounds);
}
pdf.Save("result.pdf");
Das Beispiel liefert das folgende Ergebnis für das Beispieldokument:
Sie können die folgenden Docotic.Pdf-Methoden verwenden, um detaillierte Textinformationen zu erhalten:
- PdfCanvas.GetTextData() (z. B. page.Canvas.GetTextData())
- PdfPage.GetWords()
- PdfPage.GetChars()
- PdfPage.GetObjects() (gibt nicht nur Text zurück, sondern auch Bilder und Vektorpfade)
Zugehörige GitHub-Beispiele:
- Text nach Wörtern extrahieren
- Text finden und hervorheben
- Seitenobjekte extrahieren
Rechts-nach-links- und bidirektionalen Text extrahieren
Docotic.Pdf extrahiert Arabisch, Hebräisch und Persisch aus PDF-Dokumenten korrekt.
Intern speichern PDF-Dokumente Text entsprechend der visuellen Reihenfolge. Das bedeutet, dass Text in Sprachen mit Rechts-nach-links-Schriften umgekehrt gespeichert wird. Docotic.Pdf ordnet extrahierten Text entsprechend seiner logischen Reihenfolge neu. Das ist das, was Leser von Rechts-nach-links-Text normalerweise erwarten.
Sie müssen nichts Besonderes tun. Verwenden Sie einfach die oben stehenden Codeausschnitte, um RTL-Text in der richtigen Reihenfolge zu erhalten.
OCR (Texterkennung)
Wenn die PDFs, mit denen Sie arbeiten, Bilder mit Text enthalten, können Sie den Text mithilfe der optischen Zeichenerkennung extrahieren. Die folgenden Beispiele zeigen, wie dies mit Docotic.Pdf und Tesseract geht:
- OCR PDF und Text extrahieren
- OCR PDF und in durchsuchbares Dokument umwandeln
Lesen Sie den Artikel OCR PDF in .NET für weitere Details.
Laden von Schriftarten in Cloud-Umgebungen
Die obigen Beispiele funktionieren in jeder Umgebung gut - unter Windows, Linux, macOS. Auf Cloud-Plattformen wie AWS Lambda müssen Sie möglicherweise einen zusätzlichen Konfigurationsschritt ausführen.
Es gibt PDF-Dokumente, die nicht eingebettete Schriftarten verwenden. Standardmäßig lädt Docotic.Pdf solche Schriftarten aus der systemweiten Schriftartensammlung (z. B. C:/Windows/Fonts oder /usr/share/fonts). Cloud-Plattformen können jedoch den Zugriff auf diese Schriftartensammlungen einschränken.
Sie können mit Ihrer Anwendung eine eigene Sammlung beliebter Schriftarten bereitstellen. Suchen und kopieren Sie öffentliche Schriftartdateien in Ihr Projekt. Markieren Sie alle Schriftartdateien in Ihrem .NET-Projekt mit CopyToOutputDirectory = Always. Um die Sammlung zu verwenden, initialisieren Sie PdfDocument mit einem benutzerdefinierten DirectoryFontLoader:
PdfConfigurationOptions config = PdfConfigurationOptions.Create();
config.FontLoader = new DirectoryFontLoader(["path_to_your_font_collection"], true);
using var pdf = new PdfDocument("your_document.pdf", config);
// ...
Abschluss
Sie können die Docotic.Pdf-Bibliothek verwenden, um Klartext oder formatierten Text aus PDF in C# und VB.NET zu extrahieren. Sie können auch detaillierte Informationen zu jedem Textabschnitt extrahieren. Sie können Docotic.Pdf hier herunterladen.
Sehen Sie sich die C#- und VB.NET-Beispiele zum Extrahieren von Text aus PDF an: