Extract text from PDF in C# and VB.NET
Extracting text from a PDF document is a common task for C# and VB.NET developers. You can use Docotic.Pdf library to extract text in just a few lines of code on Windows, Linux, macOS, Android, iOS, or in a cloud environment.
You will need Docotic.Pdf library to try the sample code. Get the library and a free time-limited license key on the Download C# .NET PDF library page.
There are different approaches to text extraction. Let's look at some practical examples.

Convert PDF to plain text
You may use plain text for indexing, reading, or some kind of analysis of PDF content. This sample shows how to convert PDF to text in C#:
using BitMiracle.Docotic.Pdf;
using var pdf = new PdfDocument("your_document.pdf");
string documentText = pdf.GetText();
Console.WriteLine(documentText);
PdfDocument.GetText() provides the following result for the sample document:
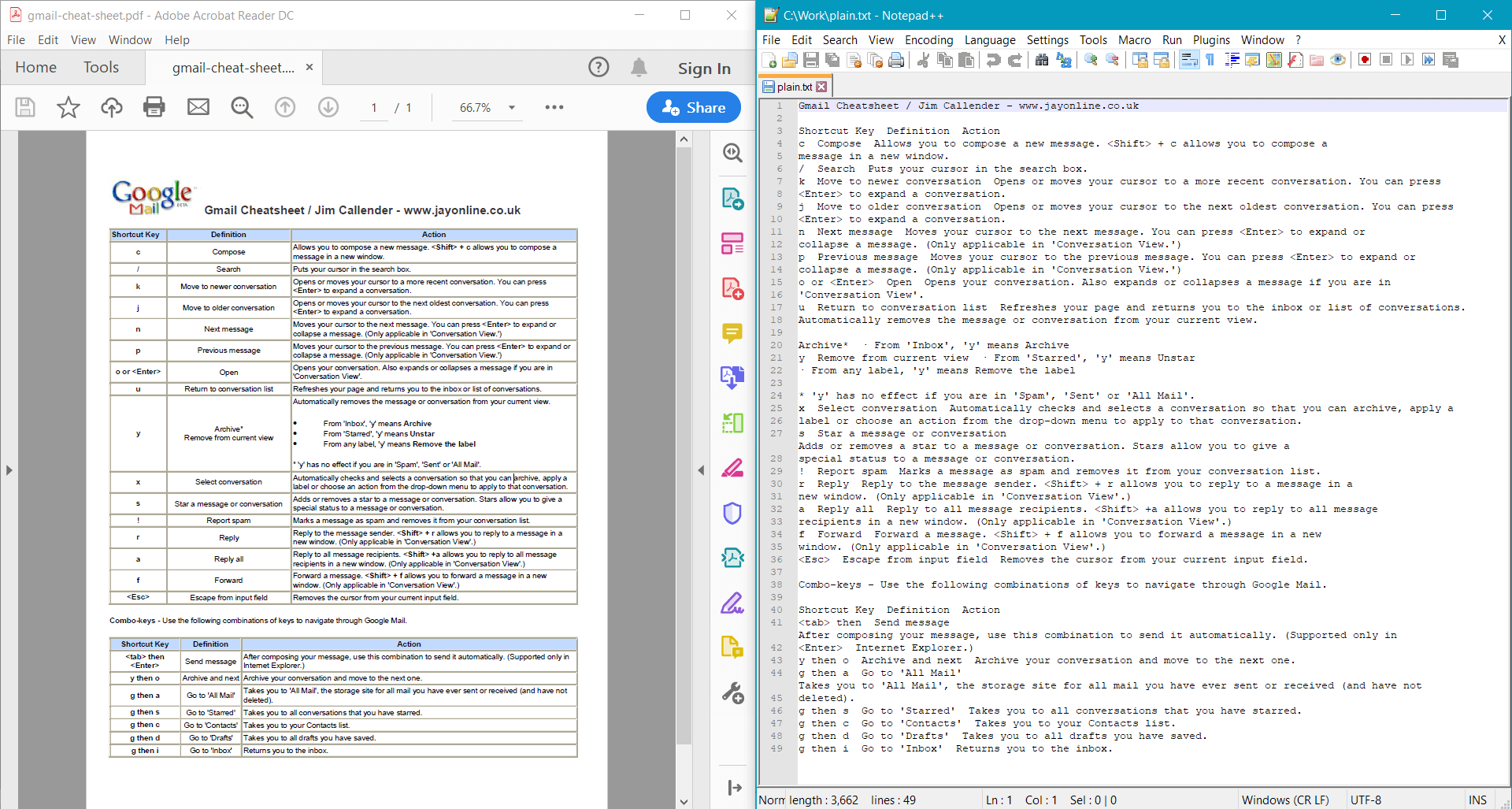
Alternatively, you can extract text from individual pages:
using var pdf = new PdfDocument("your_document.pdf");
for (int i = 0; i < pdf.PageCount; ++i)
{
string pageText = pdf.Pages[i].GetText();
using var writer = new StreamWriter($"page_{i}.txt");
writer.Write(pageText);
}
Related C# and VB.NET samples are available on GitHub.
Convert PDF to formatted text
You may use formatted text to parse some structured text data or to display the text in a human-readable format. This sample shows how to convert PDF to formatted text in C#:
using var pdf = new PdfDocument("your_document.pdf");
string formattedText = pdf.GetTextWithFormatting();
// an alternative per-page approach
_ = pdf.Pages[0].GetTextWithFormatting();
Console.WriteLine(formattedText);
PdfDocument.GetTextWithFormatting()
provides the following result for the sample document:
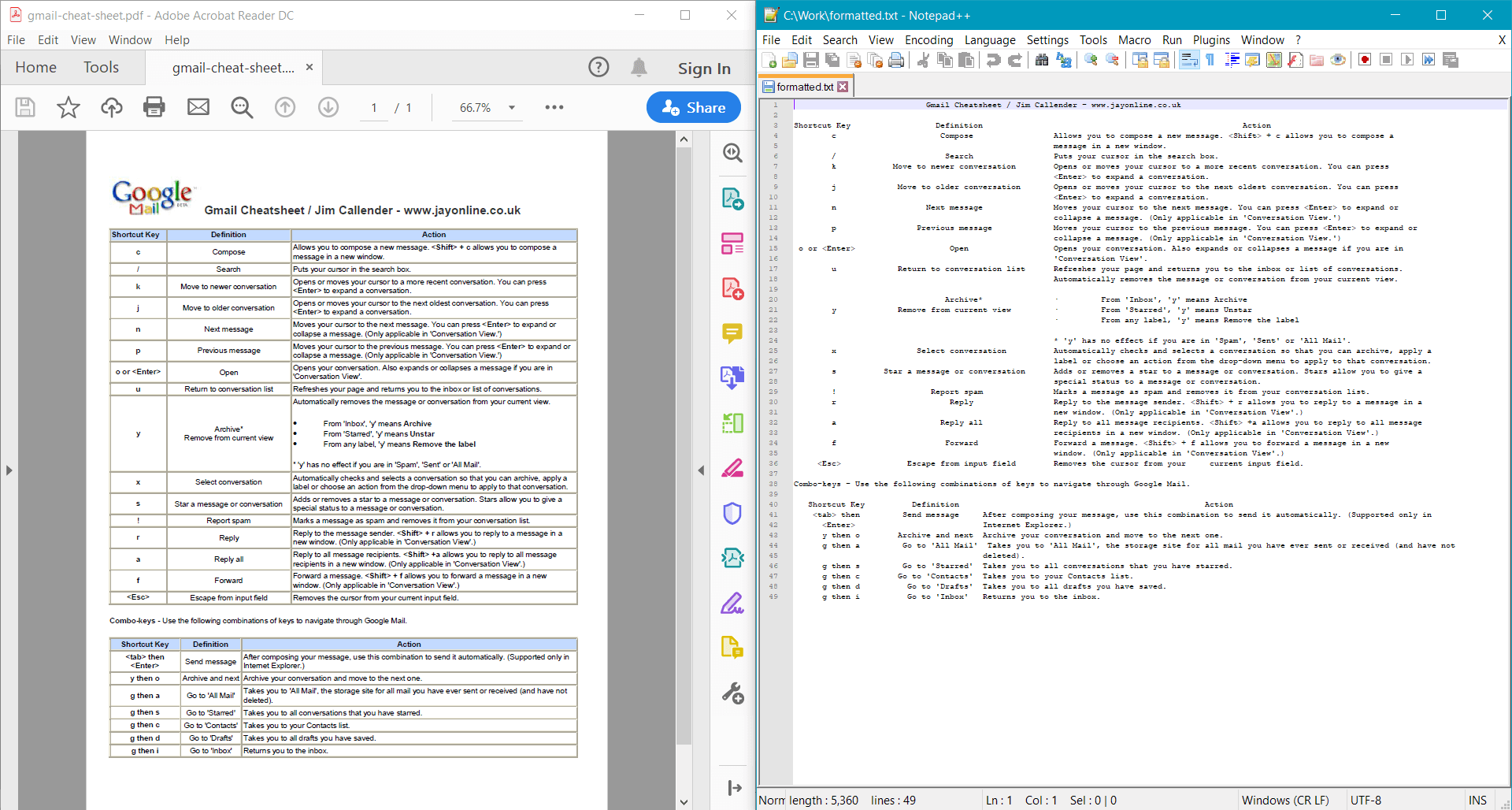
Extract plain or formatted text from a specific area
You may need to extract text from a specific part of a PDF page only. For example, to only parse the text in the page header. The library also supports this. C# sample:
using var pdf = new PdfDocument("your_document.pdf");
var page = pdf.Pages[0];
var options = new PdfTextExtractionOptions
{
Rectangle = new PdfRectangle(0, 0, page.Width, 100),
WithFormatting = false
};
string areaText = page.GetText(options);
Console.WriteLine(areaText);
This sample provides the following result for the sample document:
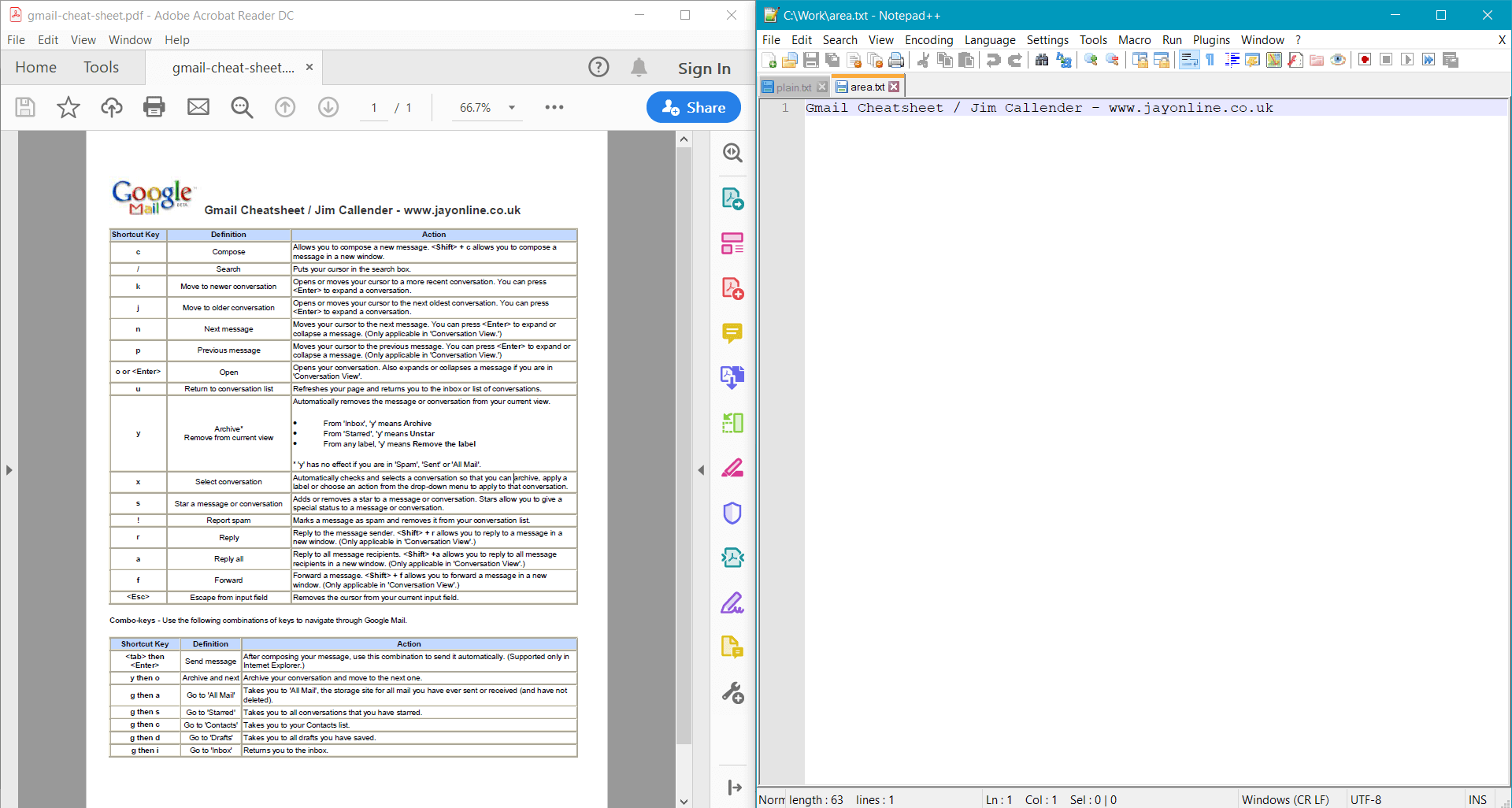
Extract detailed text information
You can also get detailed information about every text chunk for a comprehensive analysis. Docotic.Pdf provides methods for extracting text as is, by words, or by characters. For every text chunk, the library extracts:
- Unicode text
- Bounds on the page
- Font
- Font size
- Transformation matrix, which is useful for scaled and rotated text
- Rendering mode
- Fill color, opacity, pattern
- Outline style
- Detailed information about every character
This sample shows how to extract text by words from a PDF page in C#:
using var pdf = new PdfDocument("your_document.pdf");
PdfPage page = pdf.Pages[0];
foreach (PdfTextData data in page.GetWords())
{
Console.WriteLine(
$"{{\n" +
$" text: '{data.GetText()}',\n" +
$" bounds: {data.Bounds},\n" +
$" font name: '{data.Font.Name}',\n" +
$" font size: {data.FontSize},\n" +
$" transformation matrix: {data.TransformationMatrix},\n" +
$" rendering mode: '{data.RenderingMode}',\n" +
$" brush: {data.Brush},\n" +
$" pen: {data.Pen}\n" +
$"}},"
);
page.Canvas.DrawRectangle(data.Bounds);
}
pdf.Save("result.pdf");
The sample provides the following result for the sample document:
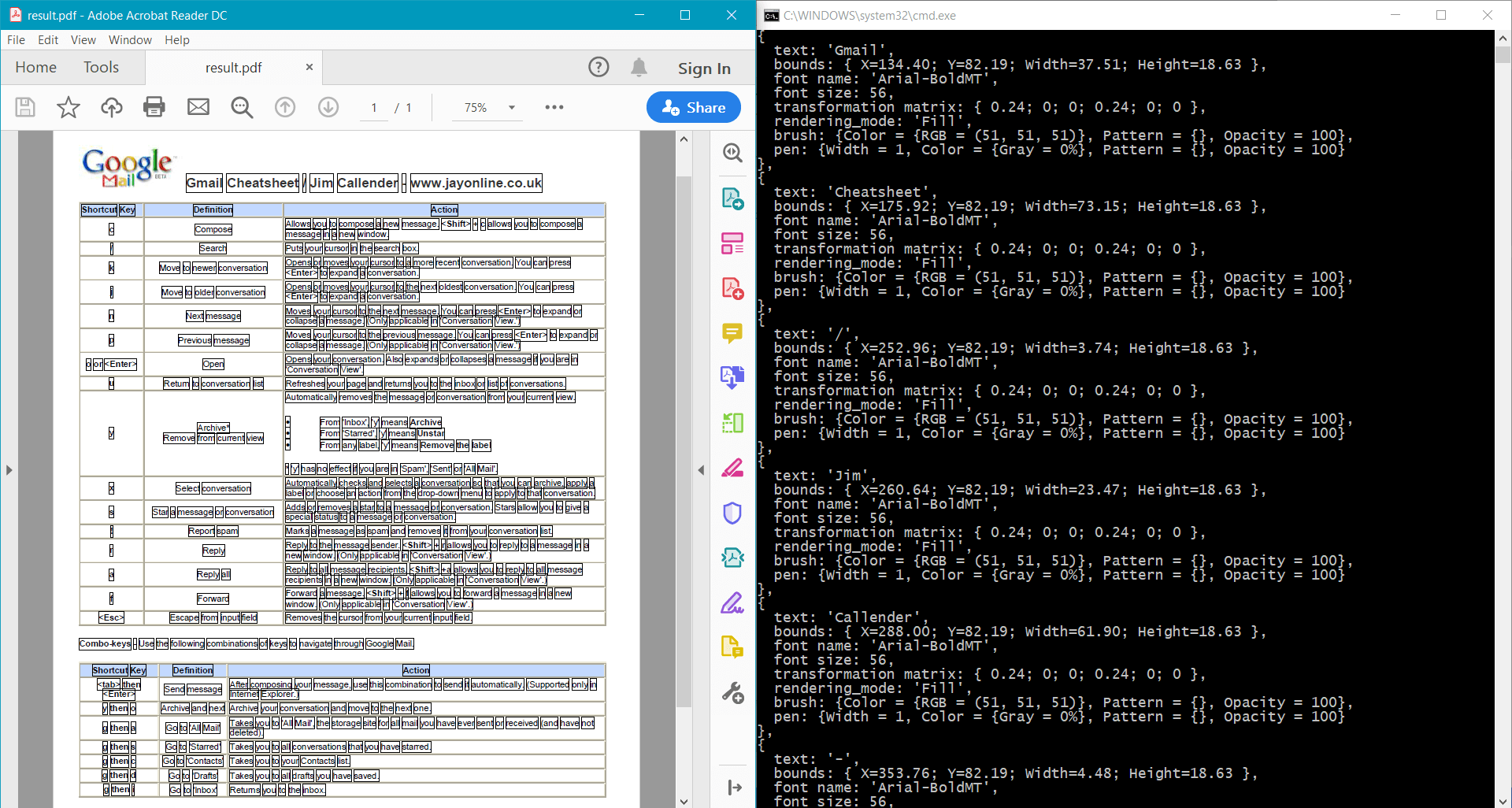
You can use the following Docotic.Pdf methods to get detailed text information:
- PdfCanvas.GetTextData() (e.g. page.Canvas.GetTextData())
- PdfPage.GetWords()
- PdfPage.GetChars()
- PdfPage.GetObjects() (returns not only text, but images and vector paths, too)
Related GitHub samples:
Extract right-to-left and bidirectional text
Docotic.Pdf properly extracts Arabic, Hebrew, and Persian text from PDF documents.
Internally, PDF documents store text according to the visual order. It means that text in languages with right-to-left scripts is stored reversed. Docotic.Pdf reorders extracted text according to its logical order. This is what readers of right-to-left text usually expect.
You don't have to do anything special. Just use the code snippets above to get RTL text in the correct order.
OCR (text recognition)
If the PDFs you deal with contain images with text, then you can extract the text using optical character recognition. The following samples show how to do that using Docotic.Pdf and Tesseract:
Look at OCR PDF in .NET article for more detail.
Font loading in cloud environments
The samples above work fine in any environment - on Windows, Linux, macOS. On cloud platforms, like AWS Lambda, you may need to do one additional configuration step.
There are PDF documents that use non-embedded fonts. By default, Docotic.Pdf loads such fonts from
the system font collection (e.g., C:/Windows/Fonts or /usr/share/fonts). However, cloud
platforms may restrict access to these font collections.
You can deploy your own collection of popular fonts with your application. Find and copy public
font files to your project. Mark all font files with CopyToOutputDirectory = Always in your .NET
project. To use the collection, initialize PdfDocument with a custom DirectoryFontLoader:
PdfConfigurationOptions config = PdfConfigurationOptions.Create();
config.FontLoader = new DirectoryFontLoader(["path_to_your_font_collection"], true);
using var pdf = new PdfDocument("your_document.pdf", config);
// ...
Conclusion
You can use Docotic.Pdf library to extract plain or formatted text from PDF in C# and VB.NET. You can also extract detailed information about every text chunk. You can download Docotic.Pdf here.
Look at C# and VB.NET samples for extracting text from PDF:
- Extract plain and formatted text
- Extract text by words
- Find and highlight text
- OCR PDF and extract text
- OCR PDF and convert to searchable document
