Esta página puede contener texto traducido automáticamente.
Extraer texto de PDF en C# y VB.NET
Extraer texto de un documento PDF es una tarea común para los desarrolladores de C# y VB.NET. Puedes usar biblioteca Docotic.Pdf para extraer texto en solo unas pocas líneas de código en Windows, Linux, macOS, Android, iOS o en un entorno de nube.
Necesitarás Docotic.Pdf library para probar el código de ejemplo. Obtén la biblioteca y una clave de licencia gratuita limitada en el tiempo en la Descargar biblioteca PDF para C# .NET página.
Hay diferentes enfoques para la extracción de texto. Veamos algunos ejemplos prácticos.

Convertir PDF a texto sin formato
Puedes usar texto sin formato para indexar, leer o realizar algún tipo de análisis del contenido del PDF. Este ejemplo muestra cómo convertir PDF a texto en C#:
using BitMiracle.Docotic.Pdf;
using var pdf = new PdfDocument("your_document.pdf");
string documentText = pdf.GetText();
Console.WriteLine(documentText);
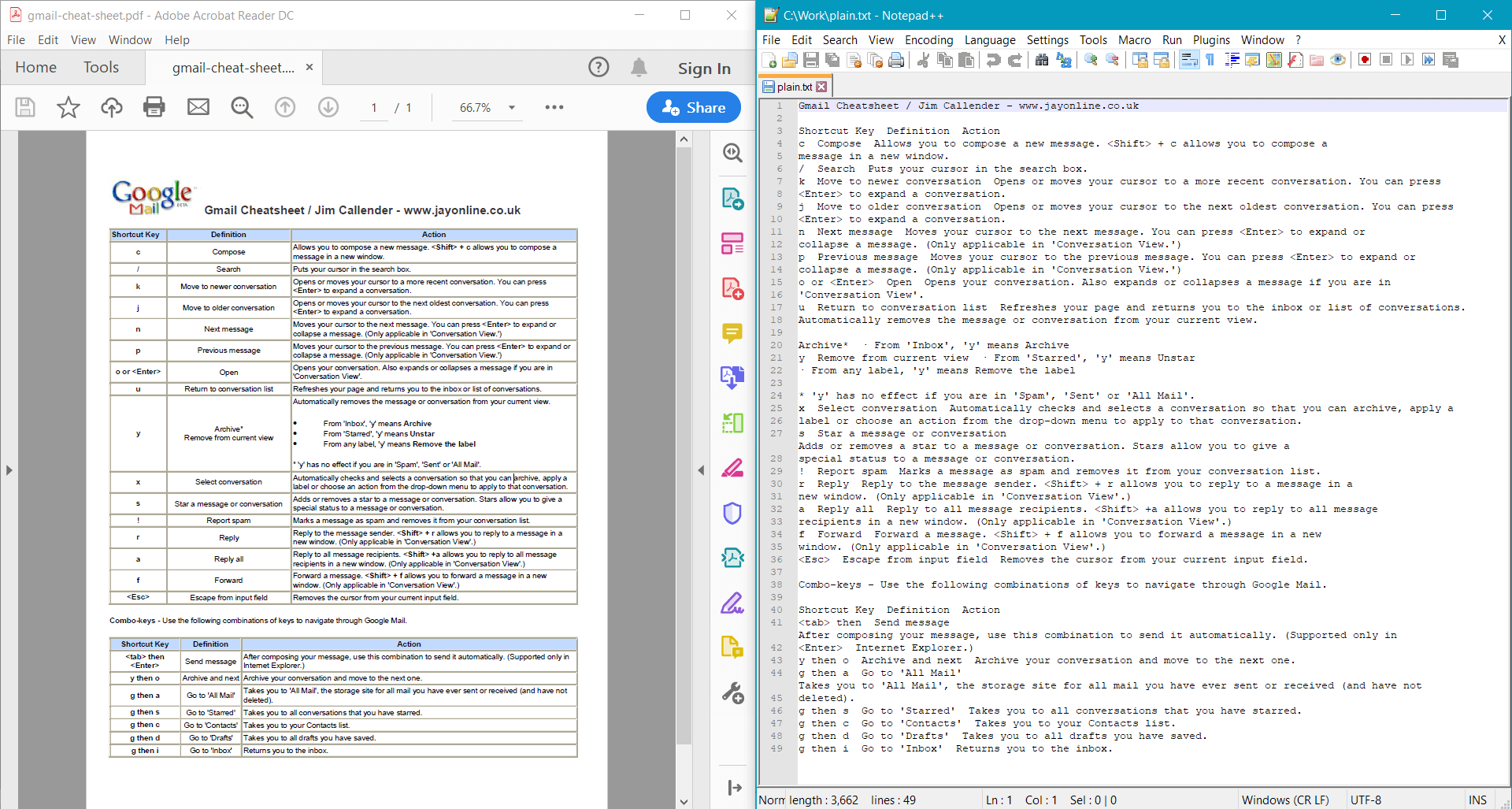
PdfDocument.GetText() proporciona el siguiente resultado para el documento de ejemplo:
De forma alternativa, puedes extraer texto de páginas individuales:
using var pdf = new PdfDocument("your_document.pdf");
for (int i = 0; i < pdf.PageCount; ++i)
{
string pageText = pdf.Pages[i].GetText();
using var writer = new StreamWriter($"page_{i}.txt");
writer.Write(pageText);
}
Hay ejemplos relacionados de C# y VB.NET disponibles en GitHub.
Convertir PDF a texto con formato
Puedes usar texto con formato para analizar algunos datos de texto estructurados o para mostrar el texto en un formato legible para personas. Este ejemplo muestra cómo convertir PDF a texto con formato en C#:
using var pdf = new PdfDocument("your_document.pdf");
string formattedText = pdf.GetTextWithFormatting();
// un enfoque alternativo por página
_ = pdf.Pages[0].GetTextWithFormatting();
Console.WriteLine(formattedText);
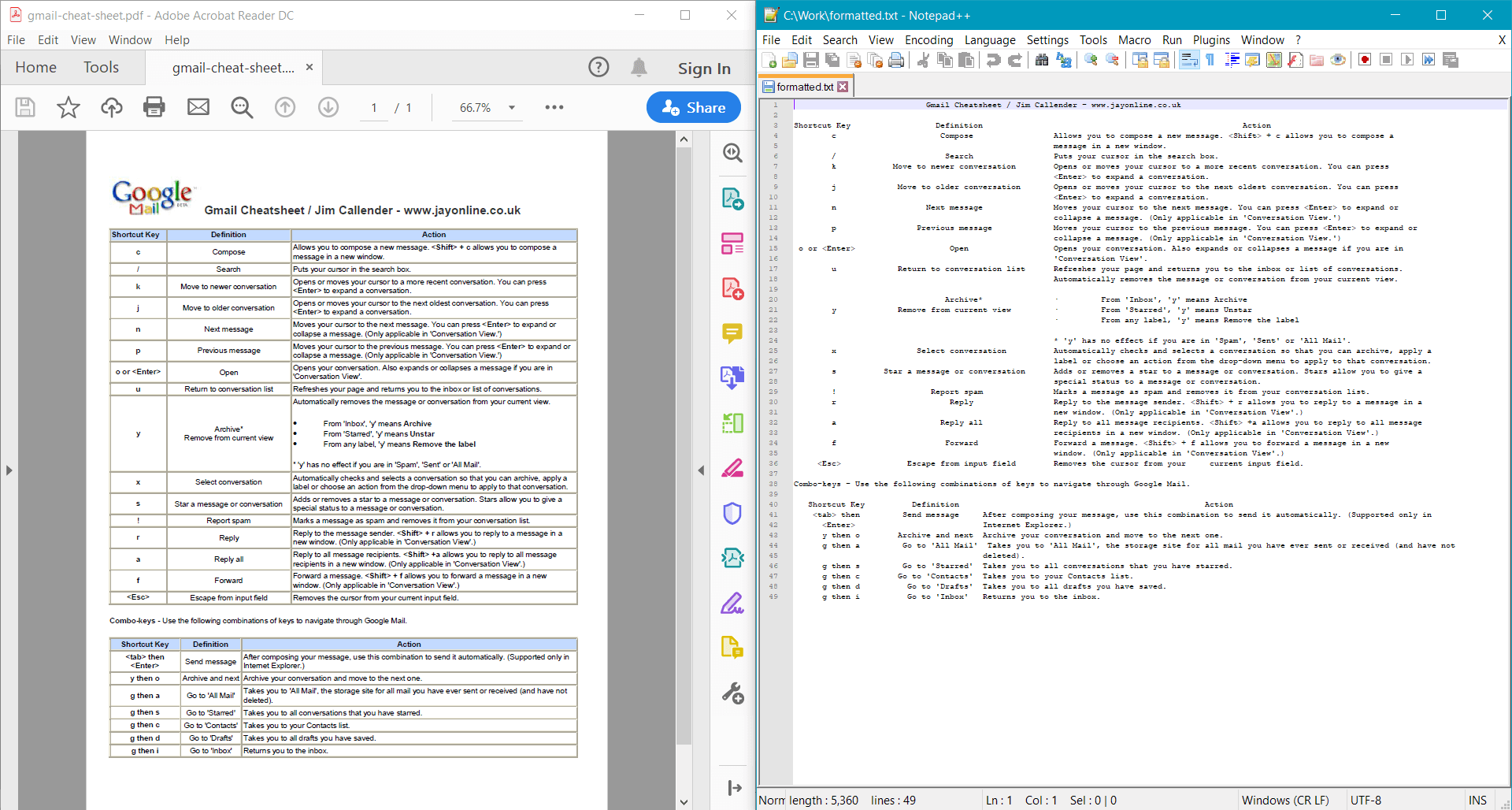
PdfDocument.GetTextWithFormatting() proporciona el siguiente resultado para el documento de ejemplo:
Extraer texto sin formato o con formato de un área específica
Es posible que necesites extraer texto solo de una parte específica de una página PDF. Por ejemplo, para analizar solo el texto del encabezado de la página. La biblioteca también admite esto. Ejemplo en C#:
using var pdf = new PdfDocument("your_document.pdf");
var page = pdf.Pages[0];
var options = new PdfTextExtractionOptions
{
Rectangle = new PdfRectangle(0, 0, page.Width, 100),
WithFormatting = false
};
string areaText = page.GetText(options);
Console.WriteLine(areaText);
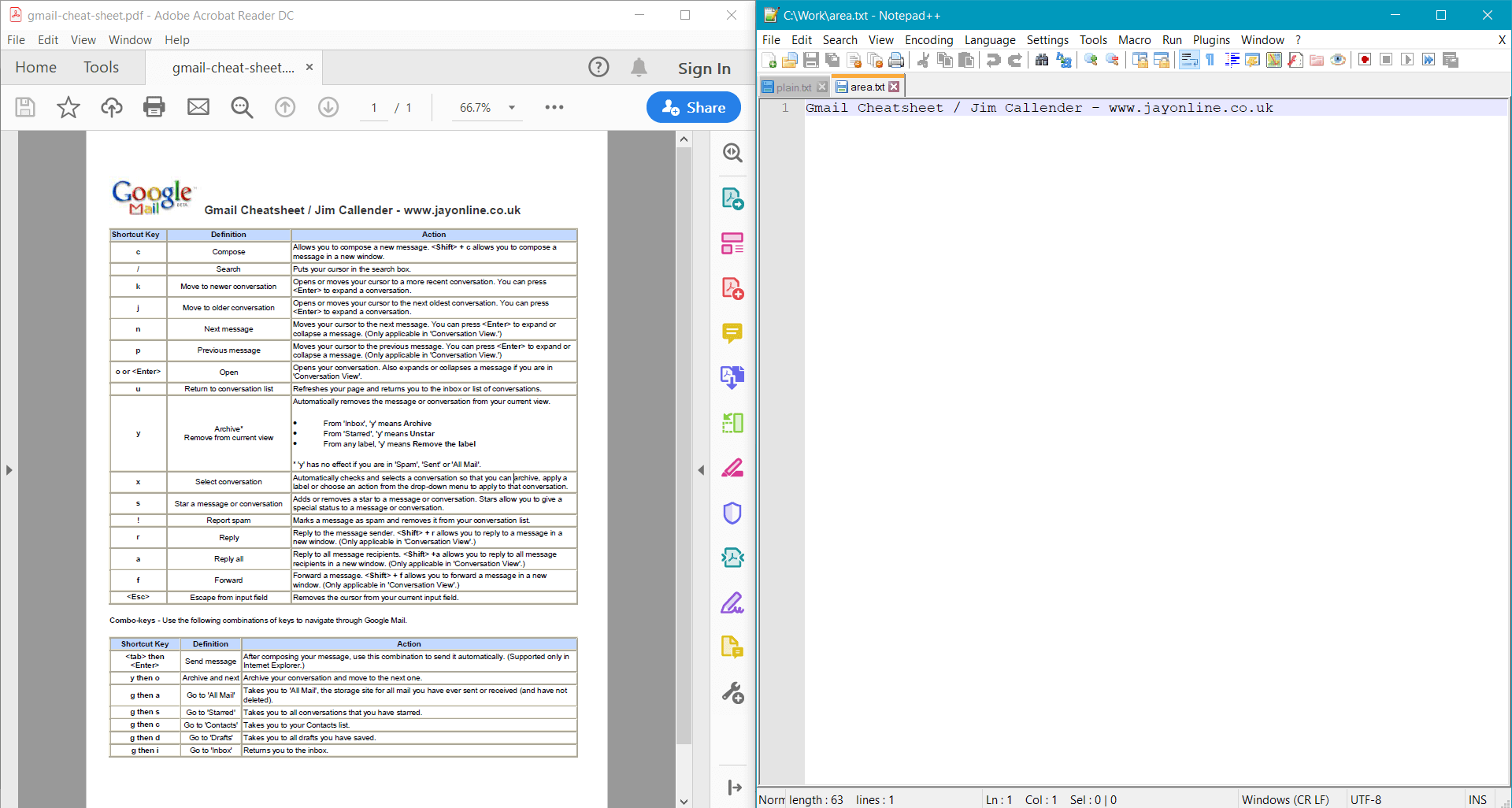
Este ejemplo proporciona el siguiente resultado para el documento de ejemplo:
Extraer información detallada de texto
También puedes obtener información detallada sobre cada fragmento de texto para un análisis completo. Docotic.Pdf proporciona métodos para extraer texto tal cual, por palabras o por caracteres. Para cada fragmento de texto, la biblioteca extrae:
- Texto Unicode
- Límites en la página
- Fuente
- Tamaño de fuente
- Matriz de transformación, que es útil para texto escalado y rotado
- Modo de renderizado
- Color de relleno, opacidad, patrón
- Estilo de contorno
- Información detallada sobre cada carácter
Este ejemplo muestra cómo extraer texto por palabras de una página PDF en C#:
using var pdf = new PdfDocument("your_document.pdf");
PdfPage page = pdf.Pages[0];
foreach (PdfTextData data in page.GetWords())
{
Console.WriteLine(
$"{{\n" +
$" text: '{data.GetText()}',\n" +
$" bounds: {data.Bounds},\n" +
$" font name: '{data.Font.Name}',\n" +
$" font size: {data.FontSize},\n" +
$" transformation matrix: {data.TransformationMatrix},\n" +
$" rendering mode: '{data.RenderingMode}',\n" +
$" brush: {data.Brush},\n" +
$" pen: {data.Pen}\n" +
$"}},"
);
page.Canvas.DrawRectangle(data.Bounds);
}
pdf.Save("result.pdf");
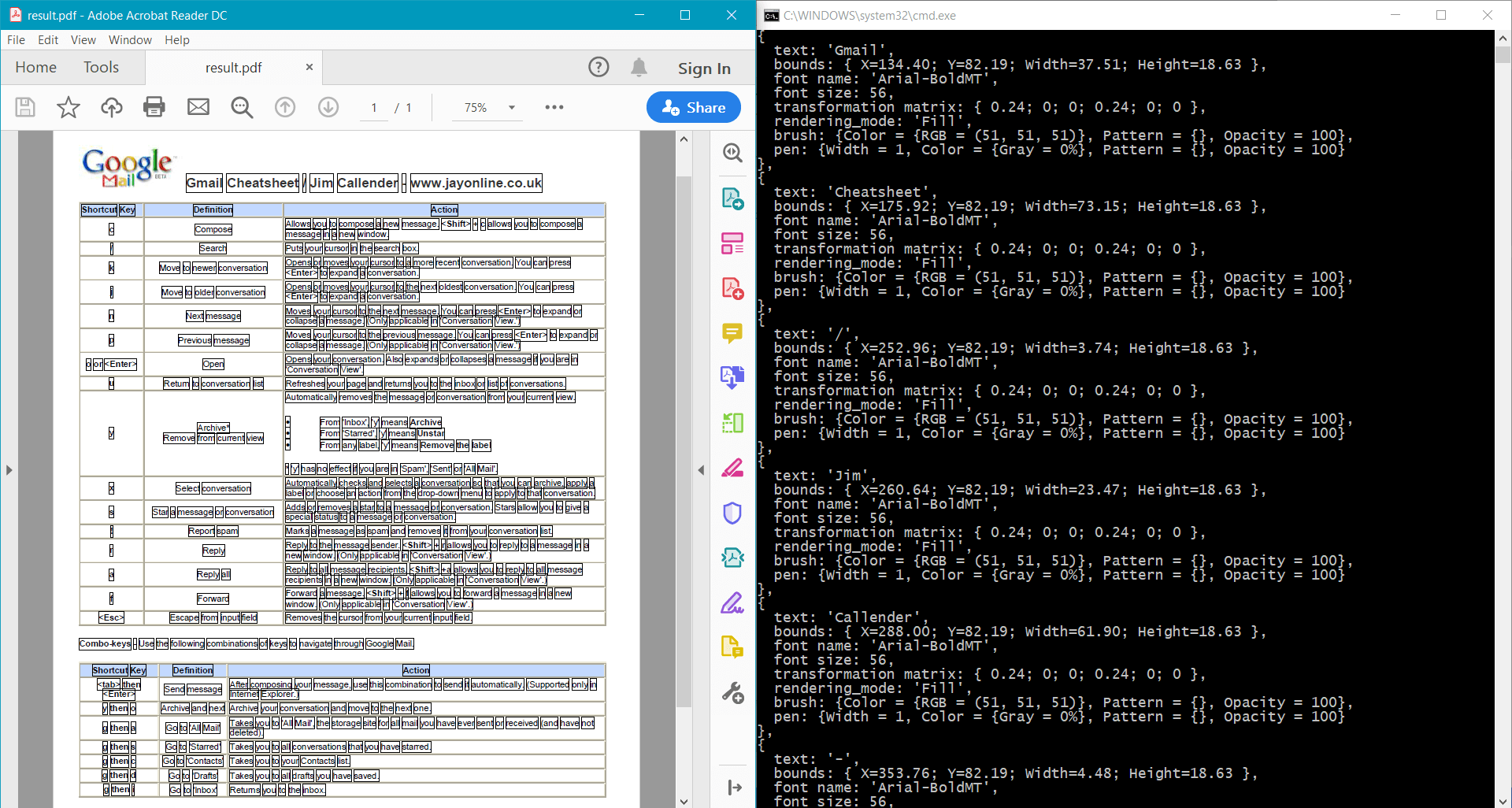
El ejemplo proporciona el siguiente resultado para el documento de ejemplo:
Puedes usar los siguientes métodos de Docotic.Pdf para obtener información detallada del texto:
- PdfCanvas.GetTextData() (p. ej., page.Canvas.GetTextData())
- PdfPage.GetWords()
- PdfPage.GetChars()
- PdfPage.GetObjects() (devuelve no solo texto, sino también imágenes y rutas vectoriales)
Ejemplos relacionados en GitHub:
- Extraer texto por palabras
- Buscar y resaltar texto
- Extraer objetos de la página
Extraer texto de derecha a izquierda y bidireccional
Docotic.Pdf extrae correctamente texto en árabe, hebreo y persa de documentos PDF.
Internamente, los documentos PDF almacenan el texto según el orden visual. Eso significa que el texto en idiomas con escrituras de derecha a izquierda se almacena invertido. Docotic.Pdf reordena el texto extraído según su orden lógico. Esto es lo que normalmente esperan los lectores de texto de derecha a izquierda.
No tienes que hacer nada especial. Solo usa los fragmentos de código anteriores para obtener texto RTL en el orden correcto.
OCR (reconocimiento de texto)
Si los PDF con los que trabajas contienen imágenes con texto, entonces puedes extraer el texto usando reconocimiento óptico de caracteres. Los siguientes ejemplos muestran cómo hacerlo usando Docotic.Pdf y Tesseract:
- OCR de PDF y extraer texto
- OCR de PDF y convertirlo en un documento con capacidad de búsqueda
Consulta el artículo OCR PDF en .NET para más detalles.
Carga de fuentes en entornos de nube
Los ejemplos anteriores funcionan bien en cualquier entorno, en Windows, Linux y macOS. En plataformas de nube, como AWS Lambda, es posible que necesites realizar un paso adicional de configuración.
Hay documentos PDF que usan fuentes no incrustadas. De forma predeterminada, Docotic.Pdf carga esas fuentes desde la colección de fuentes del sistema (por ejemplo, C:/Windows/Fonts o /usr/share/fonts). Sin embargo, las plataformas de nube pueden restringir el acceso a estas colecciones de fuentes.
Puedes implementar tu propia colección de fuentes populares con tu aplicación. Busca y copia archivos de fuentes públicas en tu proyecto. Marca todos los archivos de fuentes con CopyToOutputDirectory = Always en tu proyecto .NET. Para usar la colección, inicializa PdfDocument con un DirectoryFontLoader personalizado:
PdfConfigurationOptions config = PdfConfigurationOptions.Create();
config.FontLoader = new DirectoryFontLoader(["path_to_your_font_collection"], true);
using var pdf = new PdfDocument("your_document.pdf", config);
// ...
Conclusión
Puedes usar biblioteca Docotic.Pdf para extraer texto sin formato o con formato de PDF en C# y VB.NET. También puedes extraer información detallada sobre cada fragmento de texto. Puedes descargar Docotic.Pdf aquí.
Consulta los ejemplos de C# y VB.NET para extraer texto de PDF: