該頁面可以包含自動翻譯的文字。
使用 C# 和 VB.NET 從 PDF 中提取文本
從 PDF 文件中提取文字是 C# 和 VB.NET 開發人員的常見任務。 您可以使用 Docotic.Pdf 庫 在 Windows、Linux、macOS、Android、iOS 或雲端環境中只需幾行程式碼即可提取文 字。
您將需要 Docotic.Pdf 庫來嘗試範例程式碼。 在 下載 C# .NET PDF 函式庫 頁面取得該資料庫和免費的限時許可證金鑰。
文本提取有不同的方法。 讓我們來看一些實際的例子。

將 PDF 轉換為純文字
您可以使用純文字對 PDF 內容進行索引、閱讀或某種分析。 此範例展示如何使用 C# 將 PDF 轉換為文字:
using BitMiracle.Docotic.Pdf;
using var pdf = new PdfDocument("your_document.pdf");
string documentText = pdf.GetText();
Console.WriteLine(documentText);
PdfDocument.GetText() 為範例文 件提供以下結果:
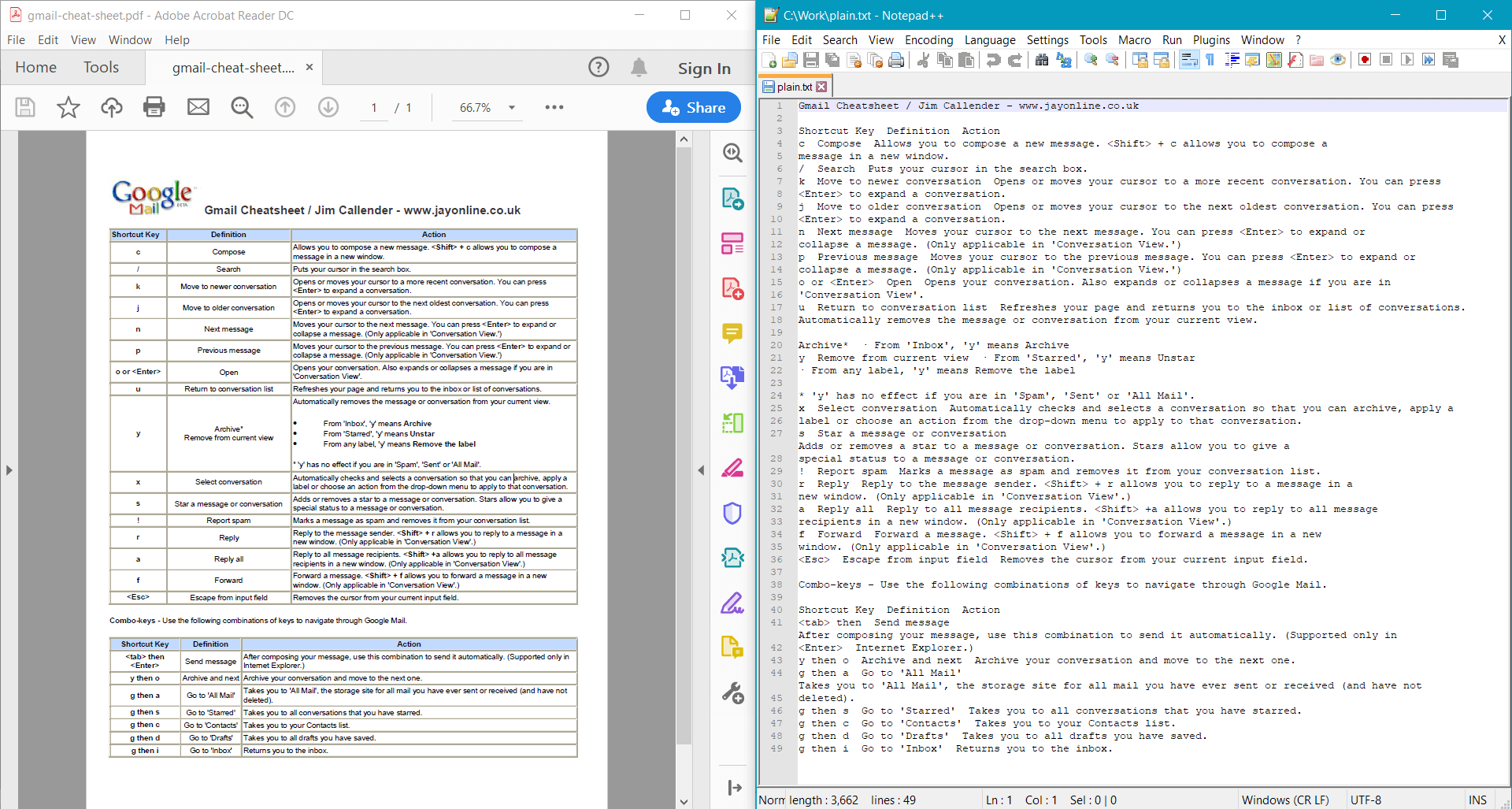
或者,您可以從各個頁面中提取文字:
using var pdf = new PdfDocument("your_document.pdf");
for (int i = 0; i < pdf.PageCount; ++i)
{
string pageText = pdf.Pages[i].GetText();
using var writer = new StreamWriter($"page_{i}.txt");
writer.Write(pageText);
}
相關的 C# 和 VB.NET 範例可在 GitHub 上取得。
將 PDF 轉換為格式化文本
您可以使用格式化文字來解析某些結構化文字資料或以人類可讀的格式顯示文字。 此範例展示如何使用 C# 將 PDF 轉換為格式化文字:
using var pdf = new PdfDocument("your_document.pdf");
string formattedText = pdf.GetTextWithFormatting();
// 一種替代的每頁方法
_ = pdf.Pages[0].GetTextWithFormatting();
Console.WriteLine(formattedText);
PdfDocument.GetTextWithFormatting() 為
範例文件提供以下結果:
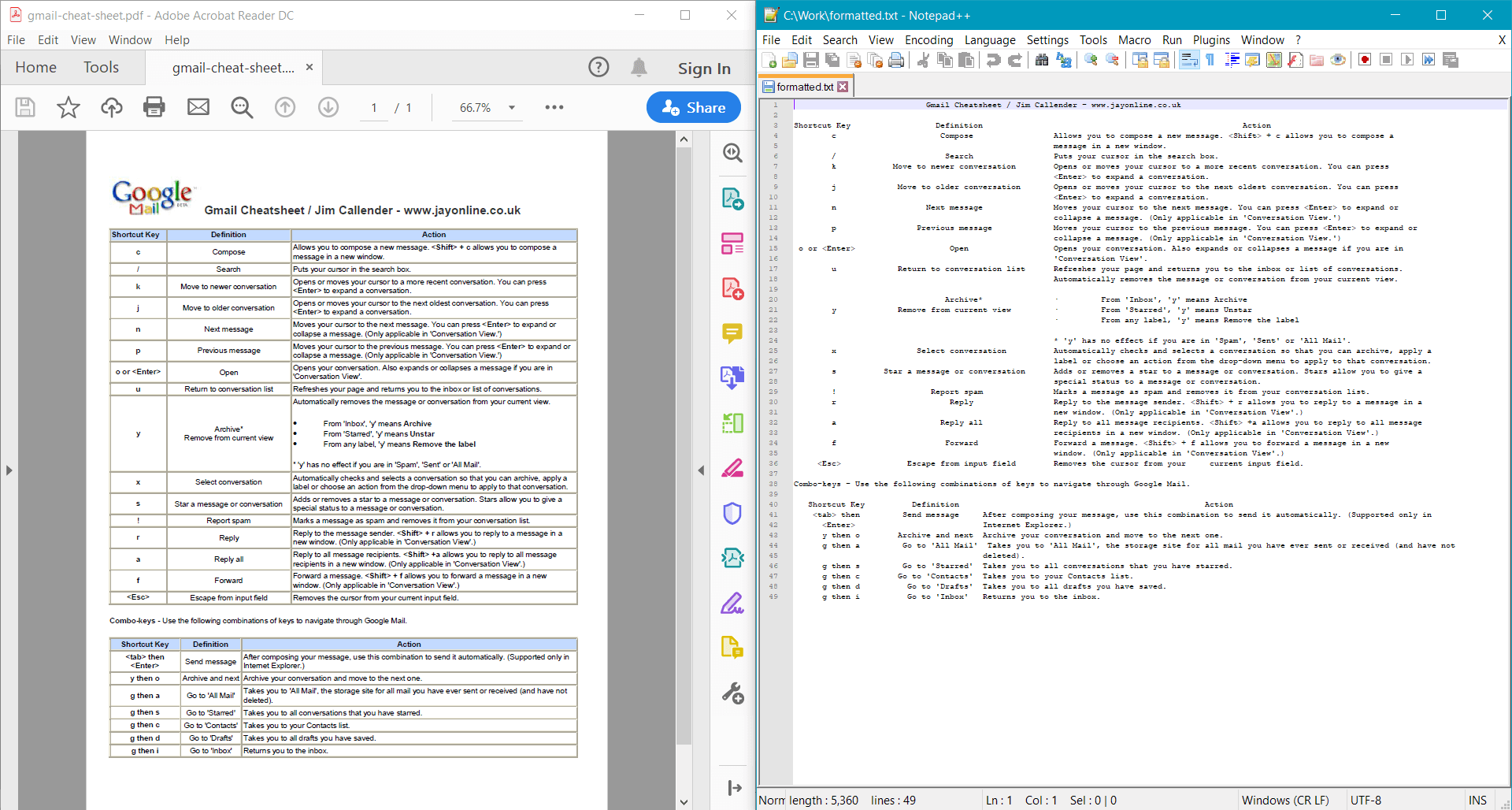
從特定區域提取純文本或格式化文本
您可能只需要從 PDF 頁面的特定部分提取文字。 例如,僅解析頁首中的文字。 圖書館也支持這一點。 C# 範例:
using var pdf = new PdfDocument("your_document.pdf");
var page = pdf.Pages[0];
var options = new PdfTextExtractionOptions
{
Rectangle = new PdfRectangle(0, 0, page.Width, 100),
WithFormatting = false
};
string areaText = page.GetText(options);
Console.WriteLine(areaText);
此範例為範例文件提供以下結果:
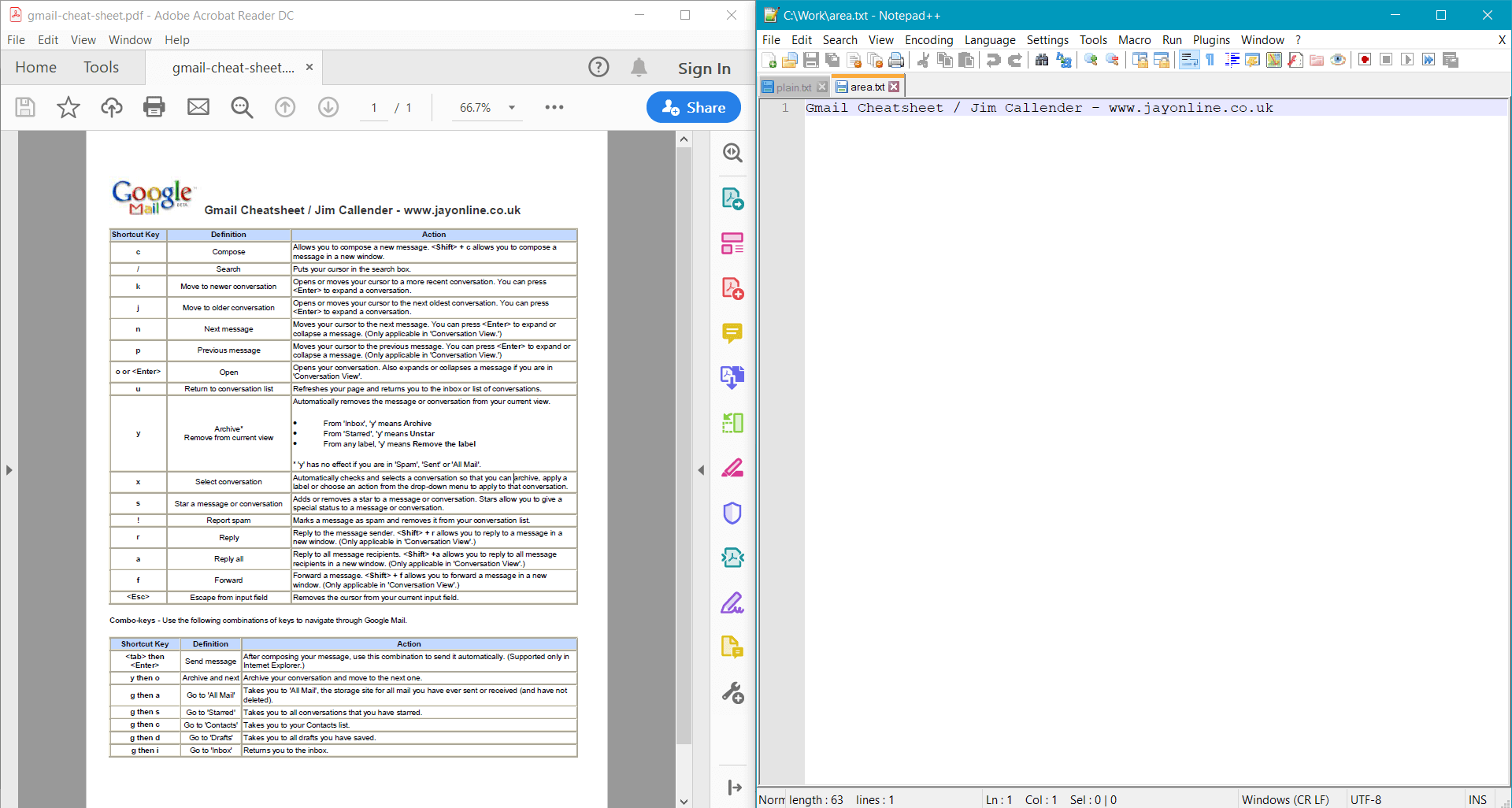
擷取詳細的文字訊息
您還可以獲得每個文本塊的詳細資訊以進行全面分析。 Docotic.Pdf 提供按單字或字元按原樣提取文字的方法。 對於每個文字區塊,該庫都會提取:
- 統一字元編碼文本
- 頁面範圍
- 字體
- 字體大小
- 變換矩陣,對於縮放和旋轉文字很有用
- 渲染模式
- 填滿顏色、不透明度、圖案
- 輪廓樣式
- 每個角色的詳細信息
此範例展示如何使用 C# 從 PDF 頁面中按單字擷取文字:
using var pdf = new PdfDocument("your_document.pdf");
PdfPage page = pdf.Pages[0];
foreach (PdfTextData data in page.GetWords())
{
Console.WriteLine(
$"{{\n" +
$" text: '{data.GetText()}',\n" +
$" bounds: {data.Bounds},\n" +
$" font name: '{data.Font.Name}',\n" +
$" font size: {data.FontSize},\n" +
$" transformation matrix: {data.TransformationMatrix},\n" +
$" rendering mode: '{data.RenderingMode}',\n" +
$" brush: {data.Brush},\n" +
$" pen: {data.Pen}\n" +
$"}},"
);
page.Canvas.DrawRectangle(data.Bounds);
}
pdf.Save("result.pdf");
此範例為範例文件提供以下結果:
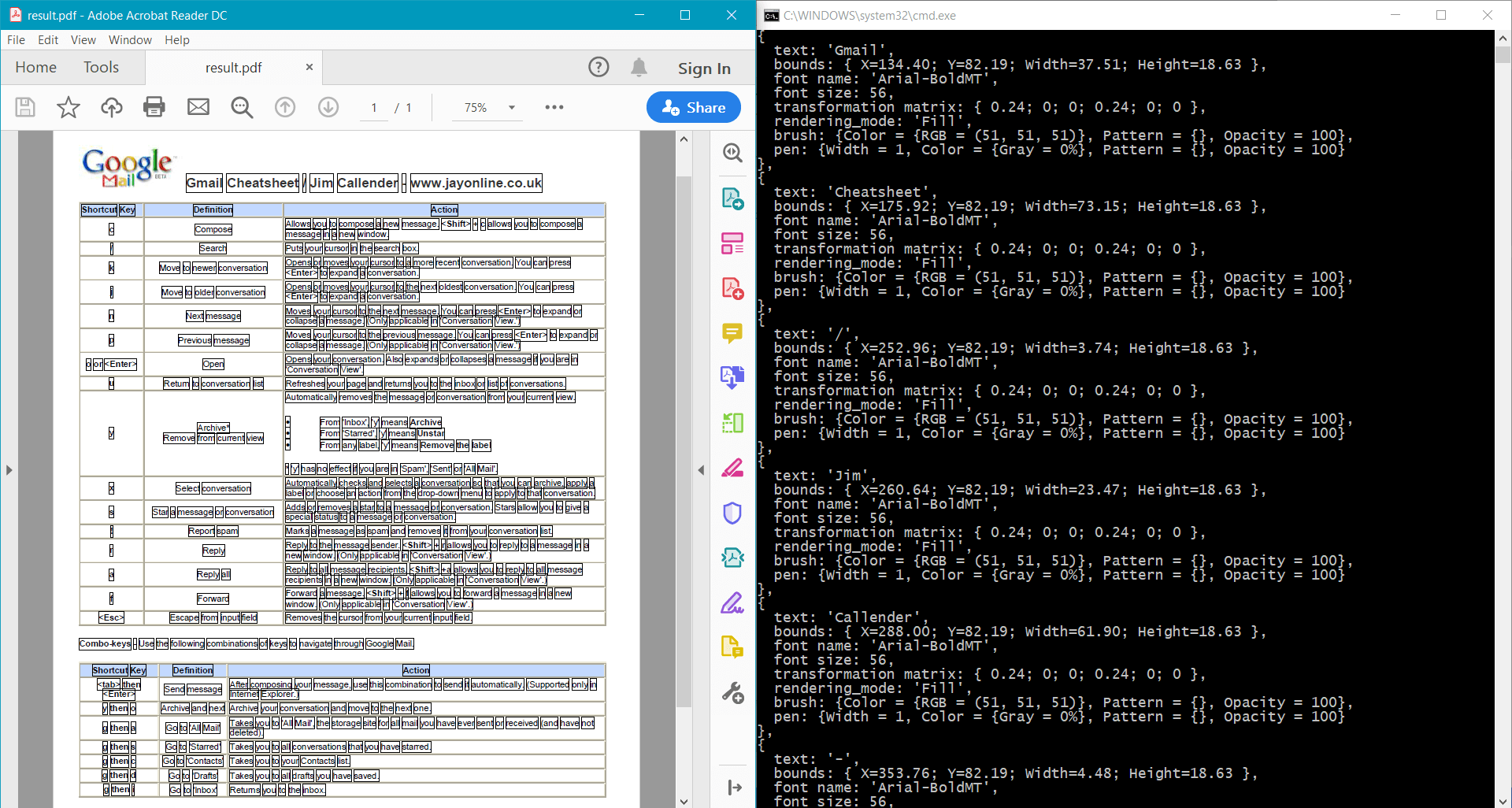
您可以使用以下 Docotic.Pdf 方法來取得詳細的文字資訊:
- PdfCanvas.GetTextData() (例如 page.Canvas.GetTextData())
- PdfPage.GetWords()
- PdfPage.GetChars()
- PdfPage.GetObjects() (不僅返回文本,還返回圖像和向量路徑)
相關 GitHub 範例:
提取從右到左和雙向文本
Docotic.Pdf 可以正確從 PDF 文件中提取阿拉伯語、希伯來語和波斯語文本。
在內部,PDF 文件根據視覺順序儲存文字。 這意味著使用從右到左腳本的語言中的文字會反向儲存。 Docotic.Pdf 根據提取的文本的邏輯順序重新排序。 這是從右到左文本的讀者通常所期望的。
你不必做任何特別的事情。 只需使用上面的程式碼片段即可以正確的順序取得 RTL 文字。
OCR(文字辨識)
如果您處理的 PDF 包含帶有文字的圖像,那麼您可以使用光學字元辨 識 擷取文字。 以下範例展示如何使用 Docotic.Pdf 和 Tesseract 執行此操作:
有關更多詳細信息,請參閱 .NET 中的 OCR PDF 文章。
雲端環境中的字體加載
上面的範例在任何環境下都可以正常工作 - Windows、Linux、macOS。 在 AWS Lambda 等雲端平台上,您可能需 要執行一項額外的設定步驟。
有些 PDF 文件使用非嵌入字體。 預設情況下,Docotic.Pdf 會從系統字體集合(例如 C:/Windows/Fonts 或
/usr/share/fonts)載入此類字體。 但是,雲端平台可能會限制對這些字體集合的存取。
您可以在應用程式中部署自己的流行字體集合。 尋找公共字體檔案並將其複製到您的專案中。 在 .NET 專案中
使用 CopyToOutputDirectory = Always 標記所有字型檔案。 若要使用該集合,請使用自訂的
DirectoryFontLoader 初始化 PdfDocument:
PdfConfigurationOptions config = PdfConfigurationOptions.Create();
config.FontLoader = new DirectoryFontLoader(["path_to_your_font_collection"], true);
using var pdf = new PdfDocument("your_document.pdf", config);
// ...
結論
您可以使用 Docotic.Pdf 庫 在 C# 和 VB.NET 中從 PDF 中提取純文字或格式化文字。 您 還可以提取有關每個文字區塊的詳細資訊。 您可以在此下載 Docotic.Pdf。
請參閱從 PDF 中提取文字的 C# 和 VB.NET 範例: