Extract text from PDF on AWS Lambda in C# .NET

Since version 5.7.9279 Docotic.Pdf can extract text from PDFs when running in AWS Lambda environment. This is true for PDFs with both embedded and non-embedded fonts. To make this possible, we added ability to use custom font loader for non-embedded fonts.
Let’s make a simple C# .NET Core application that extracts text from a PDF document and publish it to AWS Lambda.
Prerequisites
You will need the following to complete steps described in this article:
- Create AWS Lambda account here
- Visual Studio 2017 with AWS Toolkit extension
Create AWS Lambda project
In Visual Studio choose "AWS Lambda Project (.NET Core)" project template from "Visual C# -> AWS Lambda" group.
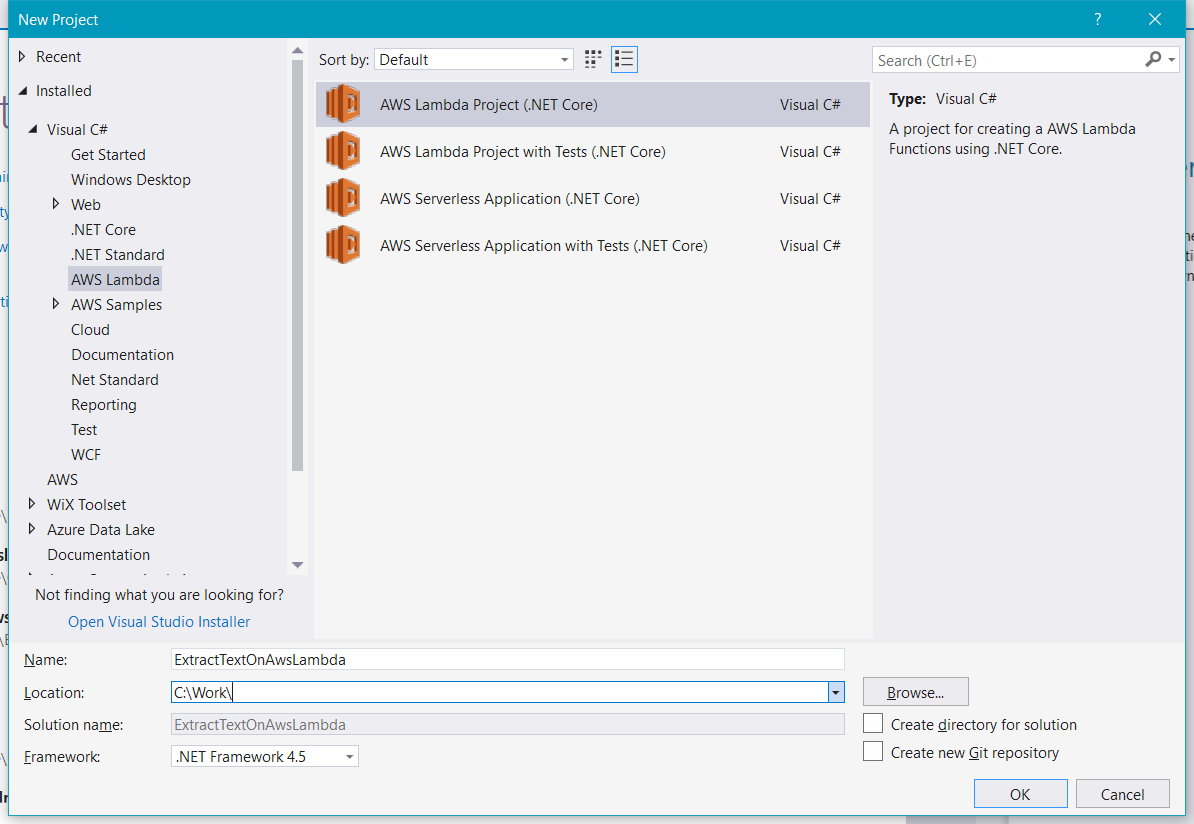
Choose "Empty function" in the "Select Blueprint" popup.
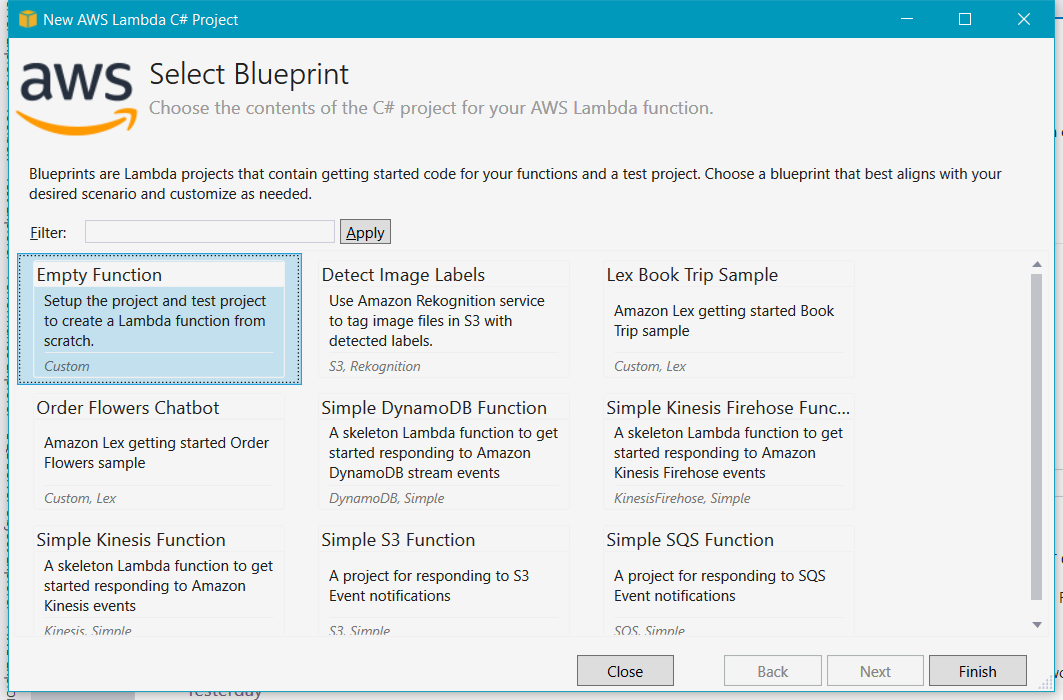
Extract text from PDF document using Docotic.Pdf library
Add Docotic.Pdf NuGet package. You should select 5.7.9279-dev version (from prerelease channel) or newer.
Add some PDF document with non-embedded TrueType/OpenType fonts to the project. For example, you can use this document.
Set "Copy to Output Directory" property for the PDF document to "Copy always".
Use the following code in Function.cs:
using Amazon.Lambda.Core;
using BitMiracle.Docotic.Pdf;
// Assembly attribute to enable the Lambda function's JSON input to be converted into a .NET class.
[assembly: LambdaSerializer(typeof(Amazon.Lambda.Serialization.Json.JsonSerializer))]
namespace ExtractTextOnAwsLambda
{
public class Function
{
public string FunctionHandler(ILambdaContext context)
{
PdfConfigurationOptions config = PdfConfigurationOptions.Create();
config.FontLoader = new DirectoryFontLoader(["/usr/share/fonts"], true);
using var pdf = new PdfDocument("Attachments.pdf", config);
return pdf.GetTextWithFormatting();
}
}
}
Replace "Attachments.pdf" with the name of the PDF file you actually use.
How the code works
Docotic.Pdf uses GdiFontLoader class by default. However, GDI+ is not installed on AWS Lambda. Because of this GdiFontLoader.Load method always throw TypeInitializationException when code runs in AWS Lambda environment.
That is why we use custom font loader in the code above. DirectoryFontLoader class scans the specified directories and loads font bytes. In this sample we use shared Linux fonts. Alternatively, you can deploy some common fonts with your application and point DirectoryFontLoader to them.
Deploy and test the function
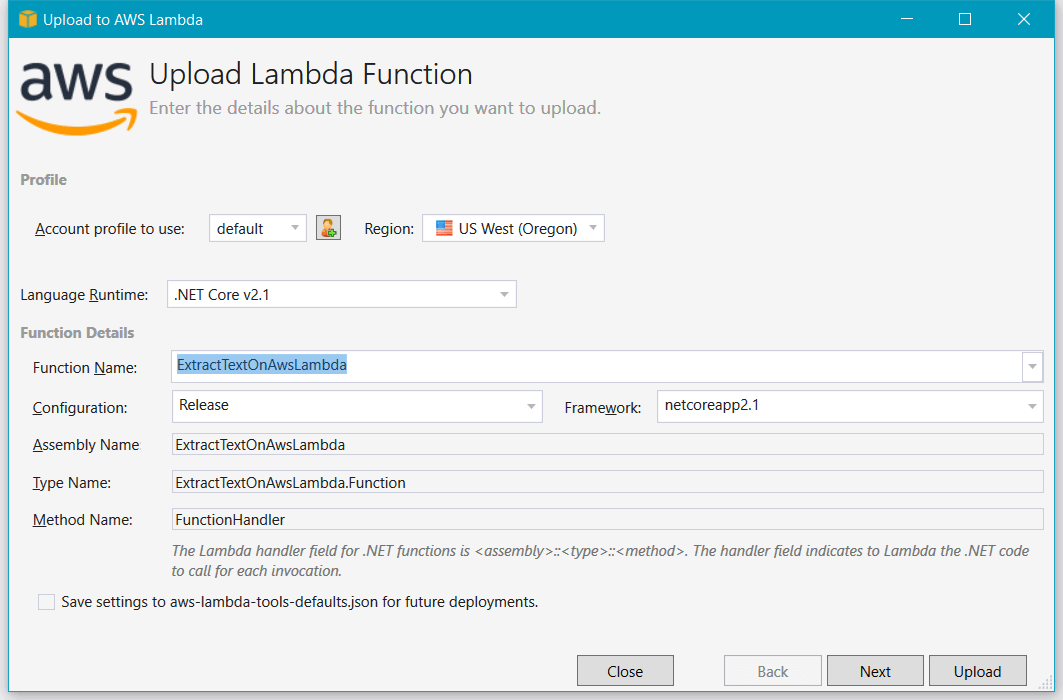
It's time to test the function on AWS Lambda. Right-click on the project in Solution Explorer and select "Publish to AWS Lambda…"
In the "Upload Lambda Function" input the name of your function. Then click "Upload".
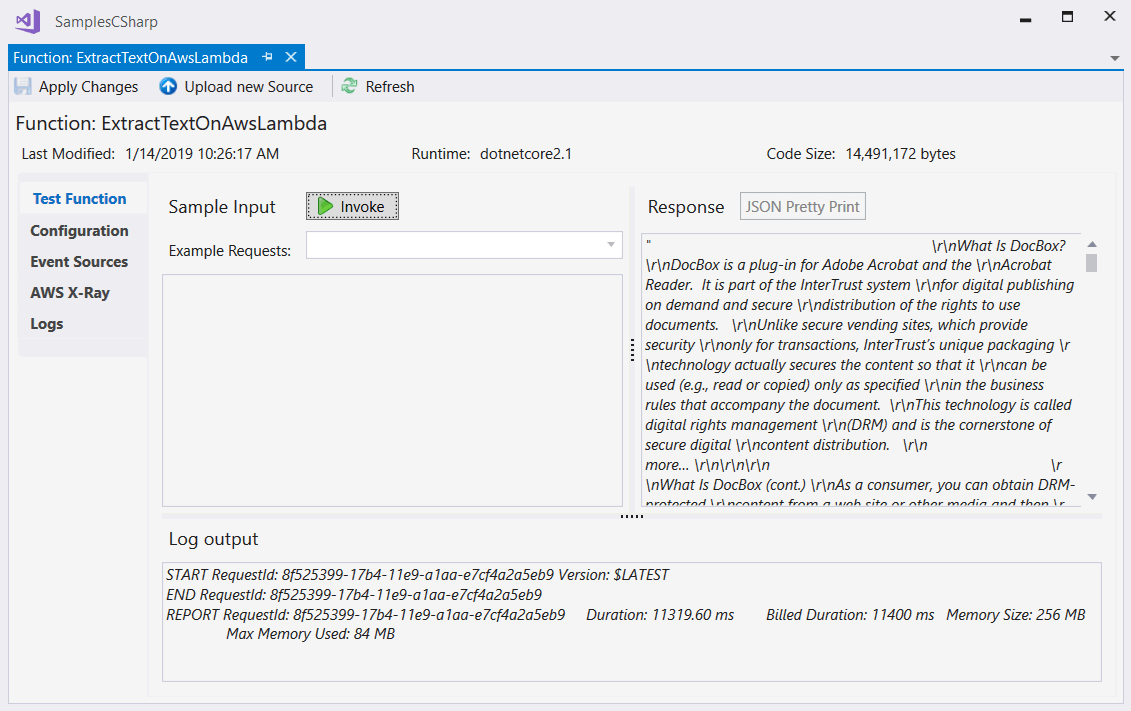
After successful deployment run the uploaded application. You will see that the text is properly extracted:

Visit our
LinkedIn page |
Telegram channel |
Google Group